
技术摘要:
一种基于优胜劣汰的深度强化学习策略网络的存储方法,该方法包括:获取当前训练周期的结果和策略网络;判断所述当前训练周期的结果是否满足策略网络测试要求;在判断所述当前训练周期的结果满足所述策略网络测试要求的情况下,进行策略网络测试;获得该策略网络测试的 全部
背景技术:
深度强化学习是机器学习中的一个分支,融合了深度学习与强化学习,较好的解 决了从低层次的感知到高层次的决策问题。深度强化学习的过程可以理解为通过深度学习 的感知能力获取环境的信息,再通过强化学习使得智能体具有一定的决策能力。强化学习 算法理论的形成可以追溯到上个世界七八十年代,几十年来强化学习算法一直在不断的更 新迭代。与常见的监督学习、无监督学习不同,强化学习的本质是一种以环境反馈作为输入 的、适应环境的机器学习方法。它模仿了自然界中人类或动物学习的基本途径,通过与环境 不断交互和试错的过程,利用评价性的反馈信号来优化所采取的行为决策。 在深度强化学习中有两个主要的组成部 ,为智能体 (A g e n t ) 和环境 (Environment)。智能体是指采用深度强化学习进行学习的事物本身,可以通过学习而自动 获取有价值信息的计算机(或者含有计算机的机器),环境是指智能体所依赖并活动、交互 的世界。在每一次智能体与环境相交互的过程中,智能体会观察当前时刻自身在环境中所 呈现的状态(State),或者部分状态,并以此为依据来决定自身在当前时刻所应该采取的行 为(Action)。同时,在每一次智能体与环境交互的过程中,智能体会从环境中接受到一个反 馈信息,这里称为奖励(Reward)。奖励是用一个具体的数值来表示,它会告诉智能体,当前 时刻其在环境的状态表现是有多好或者有多糟糕。智能体的学习目标是为了获得最大的累 计奖励,这里称为回报(Return)。深度强化学习就是一种在智能体与环境不断的信息交互 中使得智能体学习如何采取行为来达到它目标的一种方法。深度强化学习的原理如图1所 示。 深度强化学习算法的目标是使得智能体学习到最优的策略,从而最大化智能体在 单次周期内获得的累计奖励,即回报。形象来说,策略相当于智能体的大脑,控制智能体的 行为,充当智能体的控制器。策略本质上是一组带参数的可计算函数,最常用的是带有权重 参数和偏置参数的神经网络。这里用符号π表示智能体的策略,用符号θ来表示策略中的参 数,用符号πθ整体表示带参数的智能体策略。策略的输出是智能体的行为,通过梯度下降算 法来调整策略的参数,以此来改变智能体采取的行为。 智能体在单次周期内获得的回报为: 其中T表示单次周期内的总时刻数,t表示单次周期内智能体与环境进行交互的一 段完整轨迹,可以用智能体的状态-行为序列来表示: s0,a0,L,sT-1,aT-1,sT rt表示在t时刻智能体获得的回报值。st表示智能体在t时刻的状态,at表示智能体 4 CN 111582495 A 说 明 书 2/9 页 在t时刻采取的行为。R(t)表示单次周期内,智能体经历交互的轨迹t获得的回报。 深度强化学习的目标用数学的形式表示可以为: 其中E[R(t)]代表R(t)的期望值,t:πθ代表智能体与环境进行交互所得到的轨迹 依赖于当前智能体的策略πθ。J(πθ)代表深度强化学习的目标函数,即依赖于πθ的期望回报 值。 深度强化学习算法解决的本质问题是训练一个策略网络πθ,使得目标函数J(πθ)最 大化。该策略网络映射了智能体与环境交互模型的状态量与智能体行为量之间的关系,使 得智能体凭借自身当前时刻测量的状态量,计算当前时刻自身的行为量。在使用任何深度 强化学习方法完成训练之后都要面临策略网络保存的问题,因为之后需要反复使用训练好 的策略网络对智能体进行行为量的计算。 目前在深度强化学习领域中,没有专门对深度强化学习网络保存的问题做出特别 有效的方法研究。通常使用的方法有如下两种: (1)设定深度强化学习的训练周期,等待训练结束时取最终策略网络进行保存。 (2)在深度强化学习训练过程中,每间隔一定周期数对策略网络进行一次保存。训 练结束后对保存的所有网络进行比较,选择其中表现最优的策略网络进行保存。 目前常使用的两种深度强化学习网络保存方法均存在一些不足。众所周知,深度 强化学习算法并不是一种特别稳定的学习算法。由于强化学习训练原理中必须包含一定的 探索机制,导致训练过程并不是一直朝着最优的方向进行。纵然是当前所有深度强化学习 算法中表现最好的深度增强学习算法(Proximal Policy Optimization算法,简称PPO算 法),在训练时也会存在随着训练时长的增加,网络表现结果越来越差的情况。因此若是使 用第一种深度强化学习策略网络保存方法,等待训练结束后,最终得到的策略网络往往不 是整个训练过程中最优的策略网络,更严重的情况可能得到完全不能使用的策略网络。 针对这一问题,提出了第二种深度强化学习策略网络保存方法。第二种方法不是 只保存训练结束后最终的策略网络,而是在整个训练过程对策略网络进行周期性的保存, 以防训练结果由好变坏。但是使用深度强化学习进行训练通常是一个非常漫长的过程,往 往设定的训练周期数目会非常高,导致最终保存的网络数目也是相当的巨大,后期将要付 出较大的工作量对所有保存的策略网络进行筛选。同时,由于策略网络的保存依然是间断 性的,并不会保存训练过程中所有出现过的策略网络,这将导致最终筛选出来的策略网络 可能依然不是整个训练过程中表现最优的策略网络。 针对以上两种当前常用的深度强化学习策略网络保存方法存在的问题,提出了基 于优胜劣汰的深度强化学习策略网络存储方法。该机制将策略网络的筛选与训练过程融合 在一起,在训练过程中及时对策略网络进行测试、评价、筛选,在训练结束后将会保存整个 深度强化学习训练过程表现最优的策略网络。
技术实现要素:
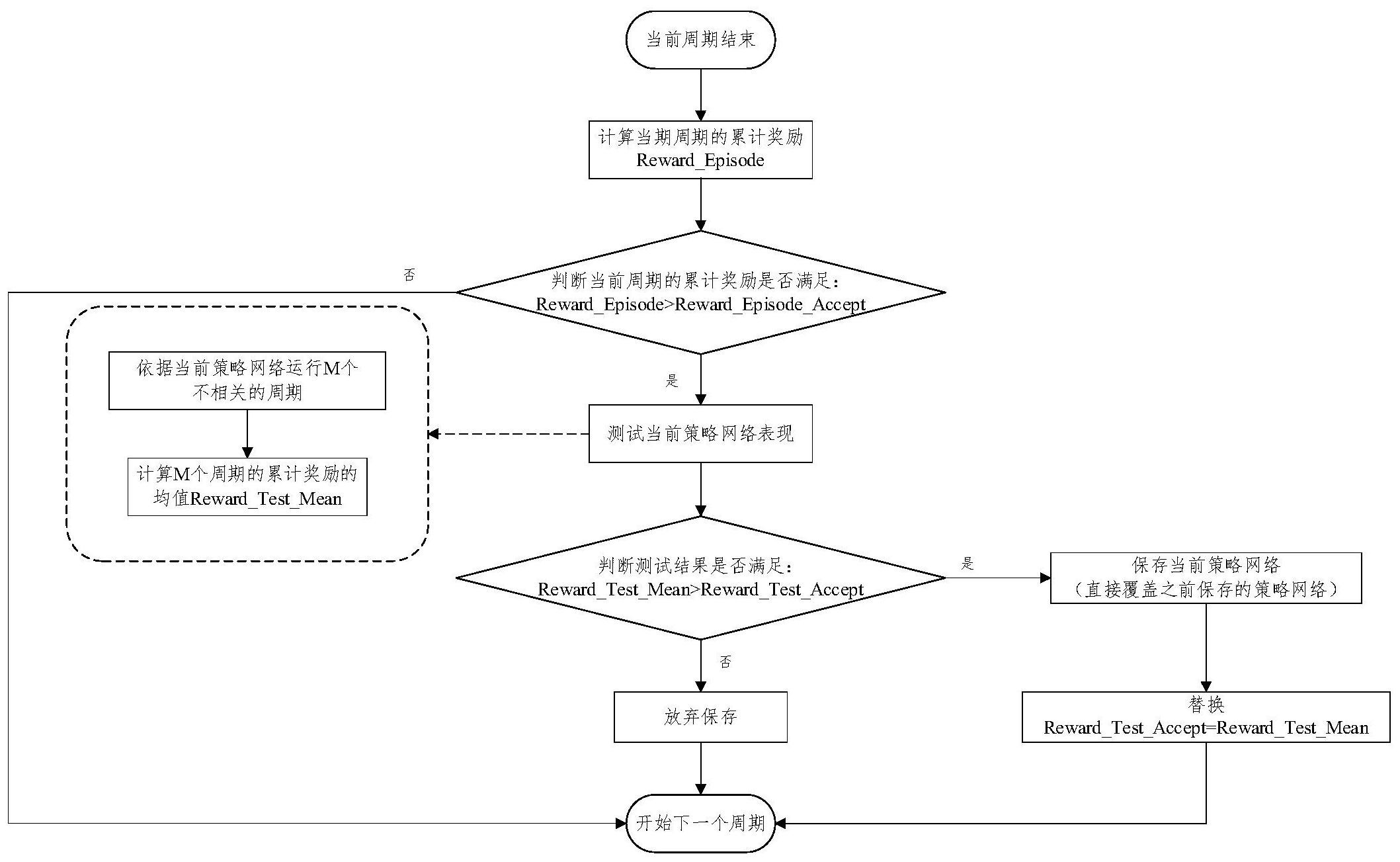
本发明针对深度强化学习中的策略网络选择并保存的问题,提出了基于优胜劣汰 的策略网络存储方法。该方法将网络的筛选与网络的训练融合在一起,在训练过程中及时 5 CN 111582495 A 说 明 书 3/9 页 对策略网络进行测试、评价、筛选,在使用深度强化学习算法完成训练时,会直接得到整个 训练过程中表现最优的网络。 根据本发明的一个实施方式提供了一种基于优胜劣汰的深度强化学习策略网络 存储方法,该方法包括以下步骤:获取当前训练周期的结果和策略网络;判断所述当前训练 周期的结果是否满足策略网络测试要求;在判断所述当前训练周期的结果满足所述策略网 络测试要求的情况下,进行策略网络测试;获得该策略网络测试的结果;判断所述策略网络 测试的结果是否满足保存要求;在判断所述策略网络测试的结果满足保存要求的情况下, 保存所述策略网络以及所述策略网络测试的结果。 可选地,根据本发明的另一个实施方式,获取当前训练周期的结果的步骤可包括 获取当前训练周期的累计奖励值。 可选地,根据本发明的另一个实施方式,判断当前训练周期的结果是否满足策略 网络测试要求的步骤包括:预设可接受的单周期累计奖励阈值;比较所述当前训练周期的 累计奖励值与该预设可接受的单周期累计奖励阈值;通过所述比较步骤确定当前训练周期 的累计奖励值是否满足策略网络测试要求。 可选地,根据本发明的另一个实施方式,在判断所述当前训练周期的结果满足所 述策略网络测试要求的情况下进行策略网络测试的步骤包括:设定周期数;以当前策略网 络运行所设定的周期数;获得将当前策略网络运行所述设定周期数的累计奖励均值作为该 策略网络测试的结果。 可选地,根据本发明的另一个实施方式,判断所述策略网络测试的结果是否满足 保存要求的步骤包括:设定可保存测试累计奖励阈值;比较所述累计奖励均值与所述可保 存测试累计奖励阈值;通过所述比较步骤确定所述策略网络测试的结果是否满足所述保存 要求。 可选地,根据本发明的另一个实施方式,在判断所述策略网络测试的结果满足保 存要求的情况下,保存所述策略网络以及所述策略网络测试的结果的步骤包括:获得所述 策略网络测试的结果满足保存要求的信息;保存所述策略网络;保存所述累计奖励均值并 以该所述累计奖励均值替代所述可保存测试累计奖励阈值。 可选地,根据本发明的另一个实施方式,在获取当前训练周期的结果和策略网络 的步骤之前还可包括:设定训练过程循环周期数目与每周期环境模型交互次数;随机初始 化策略网络;随机初始化智能体状态;以设定的交互次数进行智能体与环境交互;在训练循 环所设定的周期数目之后,在满足策略网络更新条件的情况下对策略网络进行更新迭代, 从而得到当前训练周期的结果和策略网络。 根据本发明的一个实施方式,提供了一种设备,包括:存储器、处理器及存储在所 述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器运行所述计 算机程序时执行根据本发明的实施方式的基于优胜劣汰的深度强化学习策略网络的存储 方法。 本发明与现有技术相比所具有的有益效果: (1)通过根据本发明的深度强化学习策略网络存储方法的实施方式可以得到整个 深度强化学习训练过程中表现最优的策略网络。 (2)根据本发明的深度强化学习策略网络存储方法的实施方式完整的融入深度强 6 CN 111582495 A 说 明 书 4/9 页 化学习训练过程之中,在训练的同时对策略网络进行测试、评估、保存。在训练结束时直接 得到所需的策略网络。 通过参考附图和以下说明,本发明的其它装置、设备、系统、方法、特征和优点将是 明显的。包括在本说明书中的所有的另外的这种系统、方法、特征和优点都在本发明的范围 内,且由所附权利要求保护。 附图说明 通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通 技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明 的限制。而且在整个附图中,用相同的参考符号表示相同的部件。通过参考附图可更好地理 解本发明。 图1示出了现有的深度强化学习学习原理示意图。 图2示出了根据本发明的融合策略网络保存方法的实施方式的深度强化学习方法 流程图。 图3示出了根据本发明的基于优胜劣汰的深度强化学习策略网络存储方法的实施 方式的流程图。 图4示出了Open Ai开源提供的GYM环境模型库中的立杆模型示意图。 图5(a)示出了在DDPG算法训练立杆问题的训练过程中采用根据本发明的基于优 胜劣汰的深度强化学习网络存储方法的实施方式得到的策略网络的训练过程图。 图5(b)示出了在DDPG算法训练立杆问题的训练过程中采用现有技术的深度强化 学习网络保存方法所保存最终的策略网络的训练过程图。 图6(a)示出了采用根据本发明的基于优胜劣汰的深度强化学习网络存储方法的 实施方式得到的策略网络的性能效果测试结果图。 图6(b)示出了采用现有技术的深度强化学习网络保存方法所保存最终的策略网 络的性能效果测试结果图。 图7(a1)示出了采用根据本发明的基于优胜劣汰的深度强化学习网络存储方法的 实施方式得到的策略网络单次立杆测试立杆角度变化图。 图7(a2)示出了采用根据本发明的基于优胜劣汰的深度强化学习网络存储方法的 实施方式得到的策略网络的行为控制变化图。 图7(b1)示出了采用现有技术的深度强化学习网络保存方法所保存最终的策略网 络的单次立杆测试立杆角度变化图。 图7(b2)示出了采用现有技术的深度强化学习网络保存方法所保存最终的策略网 络的行为控制变化图。











