
技术摘要:
本发明基于深度语义融合的卷积神经网络的三维语义图重建方法,是在单目相机条件下进行算法设计。该方法首先设计一个深度语义融合的卷积神经网络,对一直单目图像的每个像素点估计深度和预测语义。之后将深度估计的矩阵和语义分割的矩阵保存为深度图像和语义图像。然后 全部
背景技术:
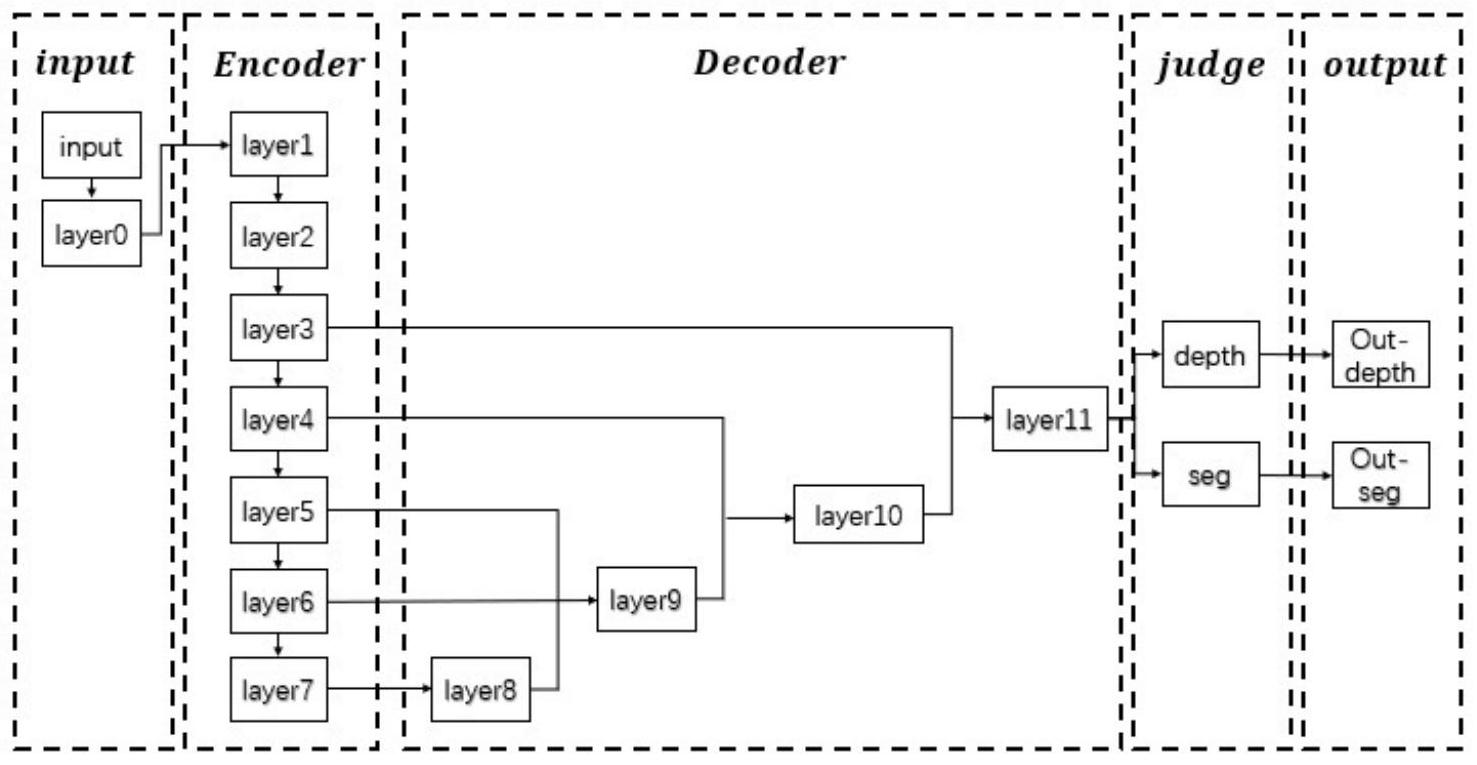
地图可以对周围环境信息进行描述,便于人类对未知环境进行理解。为了机器实 现更加深度智能化,增加自主理解周围环境的能力。因此针对三维几何地图每个像素点增 加语义信息,构建可理解的三维语义地图的研究是机器人一个有应用前景的重要方向。可 理解三维地图也称为三维语义地图,指的是对场景内采集到的数据信息,通过一定的数学 方法,生成包含空间坐标信息和语义标记信息在内的三维点云数据,给它赋予人类理解上 的含义,最终建立包含语义信息的三维地图。 近年来随着智能化移动机器人的发展,三维语义地图重建得到了国内外学者的关 注。常用的方法主要有两种方法,第一是基于深度相机对当前环境进行深度估计,建立三维 环境空间得到深度图像。然后使用深度学习对深度图像进行三维语义分割从而构建三维语 义地图。第二是对二维图像进行语义分割得到语义图像,之后融合深度图像从而构建三维 语义地图。 针对第一种方法,例如PointNet等卷积神经网络对RGB-D连续图像帧进行像素级 别的类别标记最终生成包含语义信息的稠密三维地图。虽然PointNet网络在modelnet_40 数据集的分类中达到了90%的准确率,但是只是对单一物体进行识别。在输入数据大小仅 为8192*5时,整个网络参数量为16.6M,计算量达到3633M,因此很难在更大分辨率的相机场 景中进行实用。而且它的输入点云数据是无序数据,数据之间缺少关联,没有全局信息,在 更大分辨率更复杂的输入场景中难以使用,因此在实际应用中更常使用第二种方法。 针对第二种方法,例如SemanticFusion等网络,它的缺点在于深度相机作为深度 图像获取最便捷有效的方法,在室外环境中存在很大的局限性。现如今基于深度学习不仅 在图像语义分割中取得显著成就,而且在图像深度估计的研究中也取得了良好表现,因此 可以基于深度学习进行图像深度估计。例如基于FCRN网络对连续图像推理深度信息得到深 度图像。将整个网络在NYU数据集上针对640*480分辨率的图像降采样为304*228图像后进 行训练和测试,在十米范围内的室内环境中进行深度估计可以达到0.573的平均误差。但是 基于两个网络完成语义分割和深度估计存在网络参数量过大,计算复杂的缺点。 综上所述,本发明主要的发明是基于一个卷积神经网络,同时训练和推理深度估 计和语义分割两个任务,得到深度图像和语义图像,然后将它们融合成稠密的三维语义点 云图。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种基于深度语义融合的卷积神经 网络的三维语义图重建方法,该方法基于深度语义融合的卷积神经网络完成图像深度估计 4 CN 111583390 A 说 明 书 2/12 页 和语义分割两个任务,之后将深度图像和语义图像融合成稠密三维语义点云图。实现在准 确率基本不变的基础上,减少了网络的计算的参数量和推理计算时间。 本发明采用如下技术方案来实现的: 基于深度语义融合的卷积神经网络的三维语义图重建方法,包括以下步骤: 1)选择已有的带有语义分割和深度估计的NYU数据集,将训练数据划分为训练数 据集和验证数据集; 2)搭建深度语义融合的卷积神经网络模型,使用训练数据集训练模型,当训练的 模型在验证数据集上达到设定的精度,保存网络模型参数; 3)使用训练好的模型对测试图像的每个像素点进行深度距离和语义信息的预测, 生成深度图像和语义图像; 4)融合深度图像和语义图像重建三维语义图像。 本发明进一步的改进在于,步骤2)的具体实现方法如下: 201)搭建基于深度语义融合的卷积神经网络模型时,根据数据集标签和两个任务 的特性,对网络结构进行设计; 202)训练基于深度语义融合的卷积神经网络模型时,根据数据集标签和多任务的 特性,设计损失函数进行训练。 本发明进一步的改进在于,步骤201)的具体实现方法如下: 2011)搭建基于深度语义融合的卷积神经网络模型时,分为编码层,解码层,判别 层和输出层,其中编码层对图像进行降采样提取特征,解码层进行像素点语义预测和深度 距离预测; 2012)搭建基于深度语义融合的卷积神经网络编码层时,分为三步: 第一:根据公式将图像进行标准化预处理,根据三通道的RGB自然图像统计特征, 均值img_mean每个通道取值为(0.485,0.456,0.406),方差img_std为每个通道的取值为 (0.229,0.224,0.225); 第二:使用第一层对预处理后的特征图像使用线性插值的方法缩小特征图像分辨 率,经过反复实验发现,当输出特征图像大小400*300*3分辨率时,基于深度语义融合的卷 积神经网络推理的时间和准确率效果最好; 第三:将深度可分离卷积核,BatchNorm函数,Relu激活函数通过累加设计 convbnrelu模块,将三个convbnrelu模块累加成一个block模块,按照残差计算的方式连接 所有block模块得到编码层; 2012)搭建基于深度语义融合的卷积神经网络解码层时,分为两步: 第一:对编码层得到的特征图像使用卷积核尺度大小为1的标准卷积核与窗口大 小为5的最大池化交替进行运算,得到进一步细化的特征图像; 第二:使用双线性插值对进一步细化的特征图像进行上采样,还原得到与上一层 特征图像大小相同的特征图像,将两层图像像素按照相同位置相加的方法进行融合; 2013)搭建基于深度语义融合的卷积神经网络判别层时,使用两个分支网络基于 卷积核尺度大小为1的标准卷积核,分别预测语义信息和深度距离; 5 CN 111583390 A 说 明 书 3/12 页 2014)搭建基于深度语义融合的卷积神经网络输出层时,将判别层预测的语义矩 阵和深度矩阵通过双线性插值的方法还原成与原图像分辨率相同的语义矩阵和深度矩阵。 本发明进一步的改进在于,步骤202)的具体实现方法如下: 训练基于深度语义融合的卷积神经网络模型时,按照公式设计损失函数,其中p表 示像素点语义真实值,q表示像素点语义预测值,y表示像素点深度距离真实值,f(x)表示像 素点深度距离预测值,λ为0.4; Loss(p,q,y,f(x) ,x)=-λH(p,q) (1-λ)L(y-f(x))。 本发明进一步的改进在于,步骤3)的具体实现方法如下: 301)生成语义图像时,将得到的640*480*40的语义矩阵选择每个像素概率最大的 值所在位置作为标签,转化为640*480*1的语义图像;将每一个语义标签对应一个RGB像素 值,根据对应的RGB值转化为640*480*3的语义图像; 302)生成深度图像时,将得到的640*480*1的深度矩阵每个值扩大5000倍,截取整 数部分;然后按照uint16将其进行存储,最后转化为深度图像;读取深度图像时,通过读取 像素然后缩小5000倍即可。 本发明进一步的改进在于,步骤4)的具体实现方法如下: 融合深度图像和语义图像重建三维语义图像时,读取深度图像缩小5000倍后作为 深度值,以图像左上角为坐标原点为每个像素点建立三维坐标;整合三维坐标和RGB值生成 点云数据;将所有的点云数据整合,生成点云图。 本发明至少具有如下有益的技术效果: 主要特点: 1、设计了一个深度语义融合的卷积神经网络(Semantic and Depth Fusion Convolutional Neural Networks,SDFCNN)实现图像深度估计和语义分割两个功能。 2、将得到的深度图像和语义分割融合,得到一个三维语义点云图。 主要优点: 1、SDFCNN网络基于一个卷积神经网络实现图像深度估计和语义分割两个功能。 2、SDFCNN网络对比分别完成语义分割和深度估计两个任务的深度学习网络,在保 证准确率不变的基础上减少了网络的参数来和推理时间。 附图说明 图1为深度语义融合的卷积神经网络结构示意图; 图2为双线性插值计算方法示意图; 图3为Encoder网络组成模块示意图; 图4为基于深度语义融合的卷积神经网络实现语义分割和深度估计示意图;图4中 (e)表示原图像,图4中(a)表示预测语义图像,图4中(b)表示真实语义标签图像,图4中(c) 表示预测深度图像,图4中(d)表示真实深度图像。 图5为三维语义点云图。图5中(a)表示真实深度图像和真实语义图像融合,图5中 (b)表示预测深度图像和预测语义图像融合。 6 CN 111583390 A 说 明 书 4/12 页











