
技术摘要:
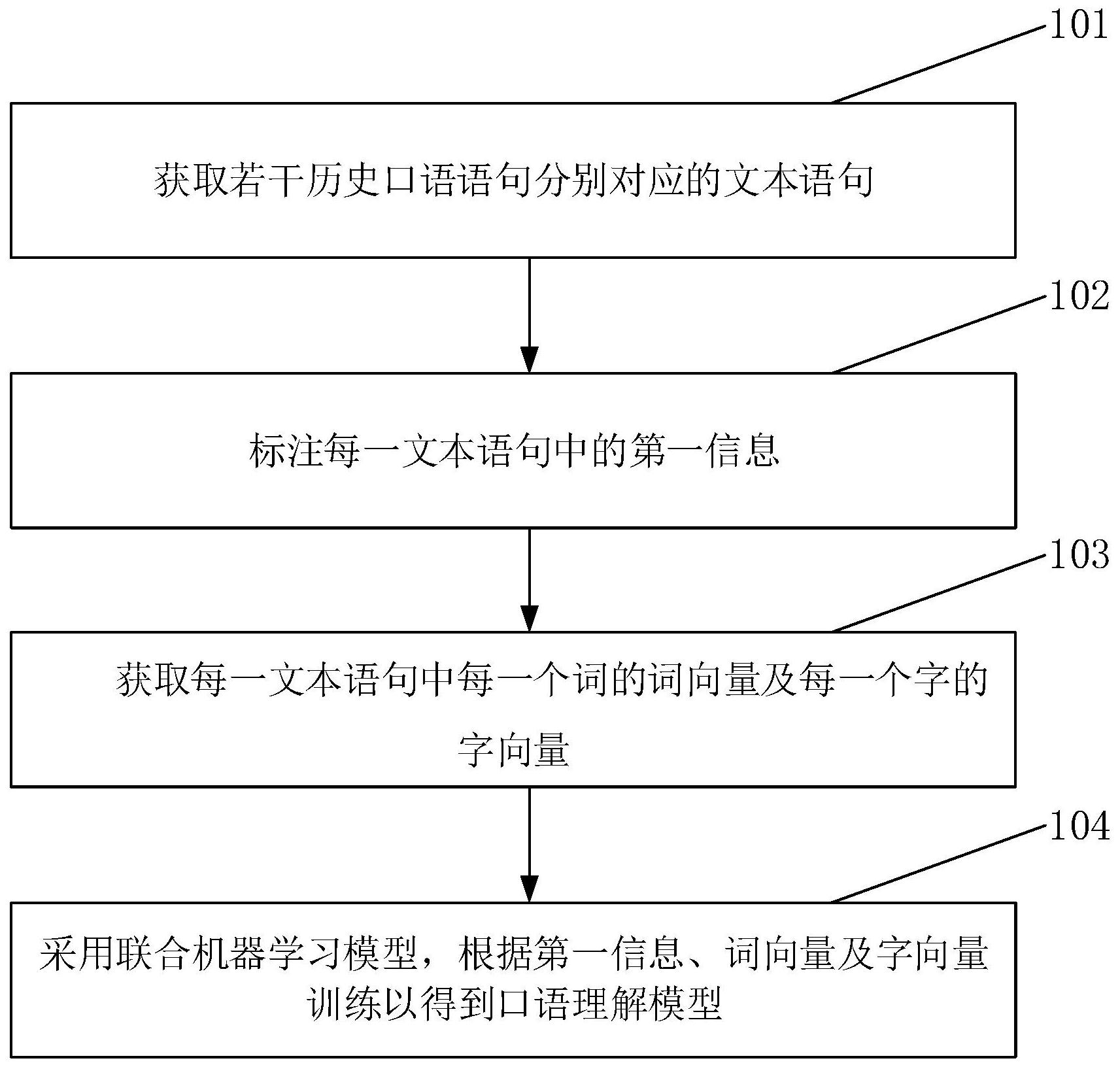
本发明公开了一种口语理解模型的训练方法、识别方法、系统、设备及介质,该训练方法包括:获取若干历史口语语句分别对应的文本语句;标注每一文本语句中的第一信息,第一信息包括用于表征文本语句中目的的标记目的信息以及存放标记目的信息对应槽位的标记槽位信息;获 全部
背景技术:
在口语识别中一般通过三块内容对口语进行理解,即Domain Classification(领 域分类)、Intent Classification(目的分类)、Slot Filling(槽填充)三块,换句话说,在 用户进行口语对话时,识别语句中的Slot Filling而后,将Intent Classification及 Domain Classification填充Slot Filling,从而达到筛选语句中的有用信息,理解口语中 的重要内容的目的,目前识别上述三块内容的主流的方法一般为pipe mode(管道模型)和 joint model(联合模型),pipe model指分别使用不同的模型对这三块内容进行建模,例如 使用SVM(一种文本分类算法)、LR(一种文本分类算法)、DNN(一种文本分类算法)等文本分 类算法来实现Domain Classification、Intent Classification,使用HMM(一种序列标注 算法)、CRF(一种序列标注算法)、RNN CRFCRF(一种序列标注算法)等序列标注算法来实现 Slot Filling。但是,现有技术中的上述方案不仅没有考虑到intent(目的)和slot(槽)之 间的相互关系,而且训练多个模型也不高效。 另一种主流方法是对它们进行联和建模,仅使用一个模型来进行识别。常用联和 建模方法通过设计联和损失函数对intent和slot进行建模,使用gate(一种神经网络)机制 来计算slot和intent的相关性从而提升slot效果,使用胶囊网络的Dynamic Routing(动态 路径)来构建slot和intent之间关系,从而达到相互促进的作用。joint model同时考虑到 了slot和intent之间的相互关系,效果往往优于pipe model。但是这种方法在对口语语义 的理解与口语的真实语义仍然存在偏差。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中在对话中对口语理解容易产生 偏差的缺陷,提供一种能准确识别理解口语中关键信息的口语理解模型的训练方法、识别 方法、系统、设备及介质。 本发明是通过下述技术方案来解决上述技术问题: 本发明提供了一种口语理解模型的训练方法,所述训练方法包括: 获取若干历史口语语句分别对应的文本语句; 标注每一所述文本语句中的第一信息,所述第一信息包括用于表征所述文本语句 中目的的标记目的信息以及存放所述标记目的信息的槽位的标记槽位信息; 获取每一所述文本语句中每一个词的词向量及每一个字的字向量; 采用联合机器学习模型,根据所述第一信息、所述词向量及所述字向量训练以得 到所述口语理解模型,所述联合机器学习模型包括若干机器学习模型组合成的模型。 本发明通过将历史口语语句中获取的文本语句中的词向量及字向量共同输入至 5 CN 111581968 A 说 明 书 2/11 页 联合机器学习模型中进行训练以得到口语理解模型。本实施例通过结合文本语句中的词的 含义及字的含义,从而能够更准确的训练出口语理解模型,进一步减小口语理解的误差。 较佳地,所述联合机器学习模型包括Attention(一种机器学习模型)机制; 采用联合机器学习模型,根据所述第一信息、所述词向量及所述字向量训练以得 到所述口语理解模型的步骤包括: 通过所述Attention机制将每一所述文本语句的每个所述字向量与每个所述词向 量对齐以生成若干对齐特征信息; 根据若干所述对齐特征信息获取融合向量; 根据所述融合向量获取第二信息; 当所述联合机器学习模型输出的每一所述第二信息与对应的所述文本语句的所 述第一信息相符时,则确定训练后的所述联合机器学习模型为所述口语理解模型。 本发明中,基于Attention机制对文本语句中的词向量和字向量进行对齐得到融 合向量,减小了ASR(自动语音识别技术)对口语识别存在误差而给文本语句理解带来的偏 差。 本发明中,通过生成融合向量可以将每一文本语句中的字的含义融入对应的词的 含义中,从而识别出更准确的第二信息。 较佳地,所述联合机器学习模型还包括第一GRU(一种神经网络模型)网络与第二 GRU网络; 通过所述Attention机制将每一所述文本语句的每个所述字向量与每个所述词向 量对齐以生成若干对齐特征信息的步骤前还包括: 将每一所述文本语句中每一个词向量,根据所述第一GRU网络生成所述词向量在 所述文本语句中的上下文向量表示; 将每一所述文本语句中每一个字向量,根据所述第二GRU网络生成所述字向量在 所述文本语句中的上下文向量表示; 通过所述Attention机制将每一所述文本语句的每个所述字向量与每个所述词向 量对齐以生成若干对齐特征信息的步骤包括: 通过所述词向量在所述文本语句中的上下文向量表示与所述字向量在所述文本 语句中的上下文向量表示对齐以生成若干对齐特征信息; 和/或, 所述联合机器学习模型还包括第三GRU网络; 根据若干所述对齐特征信息获取融合向量的步骤包括: 通过所述第三GRU网络获取每一所述对齐特征信息的上下文意思表示; 根据所有所述对齐特征信息的上下文意思表示生成所述融合向量; 和/或, 所述联合机器学习模型还包括CRF模型与Softmax(一种回归分类模型)模型; 根据所述融合向量获取所述第二信息的步骤包括: 将所述融合向量输入至所述CRF模型中以获取槽位输出信息; 将所述融合向量及所述槽位目标信息输入至所述Softmax模型中以获取目的输出 信息,所述第二信息包括所述目的输出信息及所述槽位输出信息; 6 CN 111581968 A 说 明 书 3/11 页 当所述联合机器学习模型输出的每一所述第二信息与对应所述文本语句的所述 第一信息相符时,则确定训练后的所述联合机器学习模型为所述口语理解模型的步骤包 括: 当所述槽位输出信息与所述标记槽位信息相符且所述目的输出信息与所述标记 目的信息均相符时,则确定训练后的所述机器学习模型为所述口语理解模型。 本发明中,通过GRU网络,使得融合向量中每个词以及每个字与文本语句的整体意 思相关联。 本发明中,克服了现有技术中割裂槽位信息与目的信息关系的缺陷,通过在槽位 输出信息的基础上进一步识别出目的输出信息,从而进一步提高了目的输出信息识别的准 确度。 较佳地,所述训练方法还包括: 当所述第二信息与所述第一信息不相符时,则生成误差信息,并根据所述误差信 息修改所述Attention机制中的目标参数后,执行通过所述Attention机制将每一所述文本 语句的每个所述字向量与每个所述词向量对齐以生成若干对齐特征信息、根据若干所述对 齐特征信息获取融合向量及根据所述融合向量获取所述第二信息的步骤,直至所述第二信 息与所述第一信息相符,则确定训练后的所述联合机器学习模型为所述口语理解模型。 本发明还提供了一种口语识别方法,所述口语识别方法包括: 获取用户在对话中的当前口语语句; 将所述当前口语语句输入至如上所述的口语理解模型中以得到目标信息,所述目 标信息包括目标槽位信息以及目标目的信息。 本发明中,在获取用户当前口语语句的情况下,可以根据训练出的口语理解模型 中自动识别到目标目的信息。 本发明还提供了一种口语理解模型的训练系统,所述训练系统包括:文本语句获 取模块、第一信息标注模块、向量获取模块及模型训练模块; 所述文本语句获取模块用于获取若干历史口语语句分别对应的文本语句; 所述第一信息标注模块用于标注每一所述文本语句中的第一信息,所述第一信息 包括用于表征所述文本语句中目的的标记目的信息以及存放所述标记目的信息的槽位的 标记槽位信息; 所述向量获取模块用于获取每一所述文本语句中每一个词的词向量及每一个字 的字向量; 所述模型训练模块用于采用联合机器学习模型,根据所述第一信息、所述词向量 及所述字向量训练以得到所述口语理解模型,所述联合机器学习模型包括若干机器学习模 型组合成的模型。 较佳地,所述联合机器学习模型包括Attention机制; 所述模型训练模块包括:对齐单元、融合向量获取单元、第二信息获取单元及模型 确定单元; 所述对齐单元用于通过所述Attention机制将每一所述文本语句的每个所述字向 量与每个所述词向量对齐以生成若干对齐特征信息; 所述融合向量获取单元用于根据若干所述对齐特征信息获取融合向量; 7 CN 111581968 A 说 明 书 4/11 页 所述第二信息获取单元用于根据所述融合向量获取第二信息; 所述模型确定单元用于当所述联合机器学习模型输出的每一所述第二信息与对 应的所述文本语句的所述第一信息相符时,则确定训练后的所述联合机器学习模型为所述 口语理解模型。 较佳地,所述联合机器学习模型还包括第一GRU网络与第二GRU网络; 所述训练模块还包括:第一上下文向量生成单元及第二上下文向量生成单元; 所述第一上下文向量生成单元用于将每一所述文本语句中每一个词向量,根据所 述第一GRU网络生成所述词向量在所述文本语句中的上下文向量表示; 所述第二上下文向量生成单元用于将每一所述文本语句中每一个字向量,根据所 述第二GRU网络生成所述字向量在所述文本语句中的上下文向量表示; 所述对齐单元还用于通过所述词向量在所述文本语句中的上下文向量表示与所 述字向量在所述文本语句中的上下文向量表示对齐以生成若干对齐特征信息; 和/或, 所述联合机器学习模型还包括第三GRU网络; 所述融合向量获取单元用于通过所述第三GRU网络获取每一所述对齐特征信息的 上下文意思表示,并根据所有所述对齐特征信息的上下文意思表示生成所述融合向量; 和/或, 所述联合机器学习模型还包括CRF模型与Softmax模型; 所述第二信息获取单元用于将所述融合向量输入至所述CRF模型中以获取槽位输 出信息且将所述融合向量及所述槽位目标信息输入至所述Softmax模型中以获取目的输出 信息,所述第二信息包括所述目的输出信息及所述槽位输出信息; 所述模型确定单元用于当所述槽位输出信息与所述标记槽位信息相符且所述目 的输出信息与所述标记目的信息均相符时,则确定训练后的所述机器学习模型为所述口语 理解模型。 较佳地,所述模型确定单元用于当所述第二信息与所述第一信息不相符时,则生 成误差信息,并根据所述误差信息修改所述Attention机制中的目标参数,并在修改所述目 标参数后,调用所述对齐单元、所述融合向量获取单元、所述第二信息获取单元及所述模型 确定单元直至所述模型确定单元确定所述第二信息与所述第一信息相符,则确定训练后的 所述联合机器学习模型为所述口语理解模型。 本发明还提供了一种口语识别系统,所述口语识别系统包括:当前语句获取模块 及目标输出模块; 所述当前语句获取模块用于获取用户在对话中的当前口语语句; 所述目标输出模块用于将所述当前口语语句输入至如上所述的口语理解模型中 以得到目标信息,所述目标信息包括目标槽位信息以及目标目的信息。 本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处 理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的口语理解模 型的训练方法或实现如上所述的口语识别方法。 本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机 程序被处理器执行时实现如上所述的口语理解模型的训练方法的步骤或实现如上所述的 8 CN 111581968 A 说 明 书 5/11 页 口语识别方法的步骤。 在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实 例。 本发明的积极进步效果在于: 本发明通过将历史口语语句中获取的文本语句中的词向量及字向量共同输入至 联合机器学习模型中进行训练以得到口语理解模型。本发明通过结合文本语句中的词的含 义及字的含义,从而能够更准确的训练出口语理解模型,进一步减小口语理解的误差,此 外,通过对文本语句中每一词向量及每一字向量的对齐可以更准确地训练出符合文本语句 意思的口语理解模型,进一步通过口语理解模型准确及时地识别用户的当前口语语句。 附图说明 图1为本发明实施例1的口语理解模型的训练方法的流程图。 图2为本发明实施例2中的步骤104的流程图。 图3为本发明实施例2的口语理解模型的训练方法的部分流程图。 图4为本发明实施例3的口语识别方法的流程图。 图5为本发明实施例4的口语理解模型的训练系统的模块示意图。 图6为本发明实施例5的训练模块的模块示意图。 图7为本发明实施例6的口语识别系统的模块示意图。 图8为本发明实施例7中的电子设备的结构示意图。











