
技术摘要:
本发明公开了一种基于GBP维度的mini‑GD方法,上述方法能解决现有技术中的推荐方法存在没有办法结合基因维度进行学习,计算学习时占用大量内存,在进行优化时,震荡数值偏大,数据批量运算时,无法进行整体梯度优化的问题,基于GBP维度的最小梯度下降算法对数据进行梯 全部
背景技术:
随着电子商务网站的快速发展,推荐系统已经被广泛研究和应用,推荐系统通过 提取分析用户的资料、行为、评分等信息,获得用户的喜好,来帮助电商找到特定的用户为 其推荐可能购买的产品,增加商品的销售量。 推荐系统通过收集用户的历史评分、交互(浏览、收藏、“点赞”,“踩”等交互行为)、 用户肖像(年龄、职业、性别等)、社交网络和上下文(时间、位置、活动状态、周围人员等)等 数据,对用户的历史兴趣及偏好进行分析,挖掘出用户喜欢的项目(视频、音频、书籍、菜品、 Web服务等信息),然后主动地将相关信息推荐给用户,满足用户的个性化需求。推荐算法是 推荐系统的核心,很大程度上决定了推荐系统的性能。目前主要的推荐算法包括基于内容 的推荐、基于知识的推荐、基于关联规则的推荐、协同过滤推荐和组合推荐等。 目前被广泛研究的推荐系统有的是采用基于内容的推荐算法、协同过滤推荐算法 等。基于内容的推荐算法是通过用户购买过的产品的特征,为用户推荐与其相似的产品。这 种算法的优点是可以处理冷启动问题,处理新加入的产品,并且这种算法不会受到打分稀 疏性的问题,因为它不依赖于用户对产品的评分。但是它的缺点是无法处理像图形、视频和 音乐这种难以分析提取内容特征的商品。 协同过滤算法则是利用用户-产品评分矩阵,计算用户或产品之间的相似度,利用 相似度较高的邻居对其他产品进行评分预测,并根据预测评分的高低为目标用户进行推 荐。但是每一个用户购买的产品数量通常不到产品总数的1%,所以造成用户-产品评分矩 阵非常稀疏,从而使得推荐结果不佳;而基于邻域的协同过滤推荐算法是应用最早的协同 过滤推荐技术,代表性算法为基于用户的协同过滤推荐和基于项目的协同过滤推荐。然而 随着用户规模和项目数量的快速增长,基于邻域的协同过滤推荐算法的计算量大规模增 大,同时产生了严重的评分数据稀疏性问题,即评分稀疏性问题。为了处理可扩展性和评分 稀疏性问题,一些研究学者提出采用基于矩阵分解模型的推荐算法。矩阵分解模型假定“用 户—项目”评分矩阵可以被分解为低维的潜在特征矩阵的乘积,其中潜在特征用于表示用 户偏好或项目特征,如在电影推荐中,这些特征可能为喜剧、悬疑剧、爱情剧因素等。多次国 际性比赛和大量研究都验证了矩阵分解模型具有抗数据稀疏性、易编程、较低的时空复杂 度、较高的推荐精度和良好的可扩展性等优点。 虽然上述推荐方法各有优势,但是,上述推荐方法因为随着机器学习模型越来越 复杂,参数越来越多,很难求出一个具体的公式直接解出最佳的优化参数,其次,像多元线 性回归的正规方程(XTX)-1XTY,算法复杂度太高,既要算矩阵乘法,还要求矩阵的逆,计算量 4 CN 111581524 A 说 明 书 2/5 页 会很大,算法复杂度达到了O(n3),导致现有技术中的推荐方法存在没有办法结合基因维度 进行学习,计算学习时占用大量内存,在进行优化时,震荡数值偏大,数据批量运算时,无法 进行整体梯度优化的问题,因而,我们需要一个简单的方法能更快的计算出最佳参数。
技术实现要素:
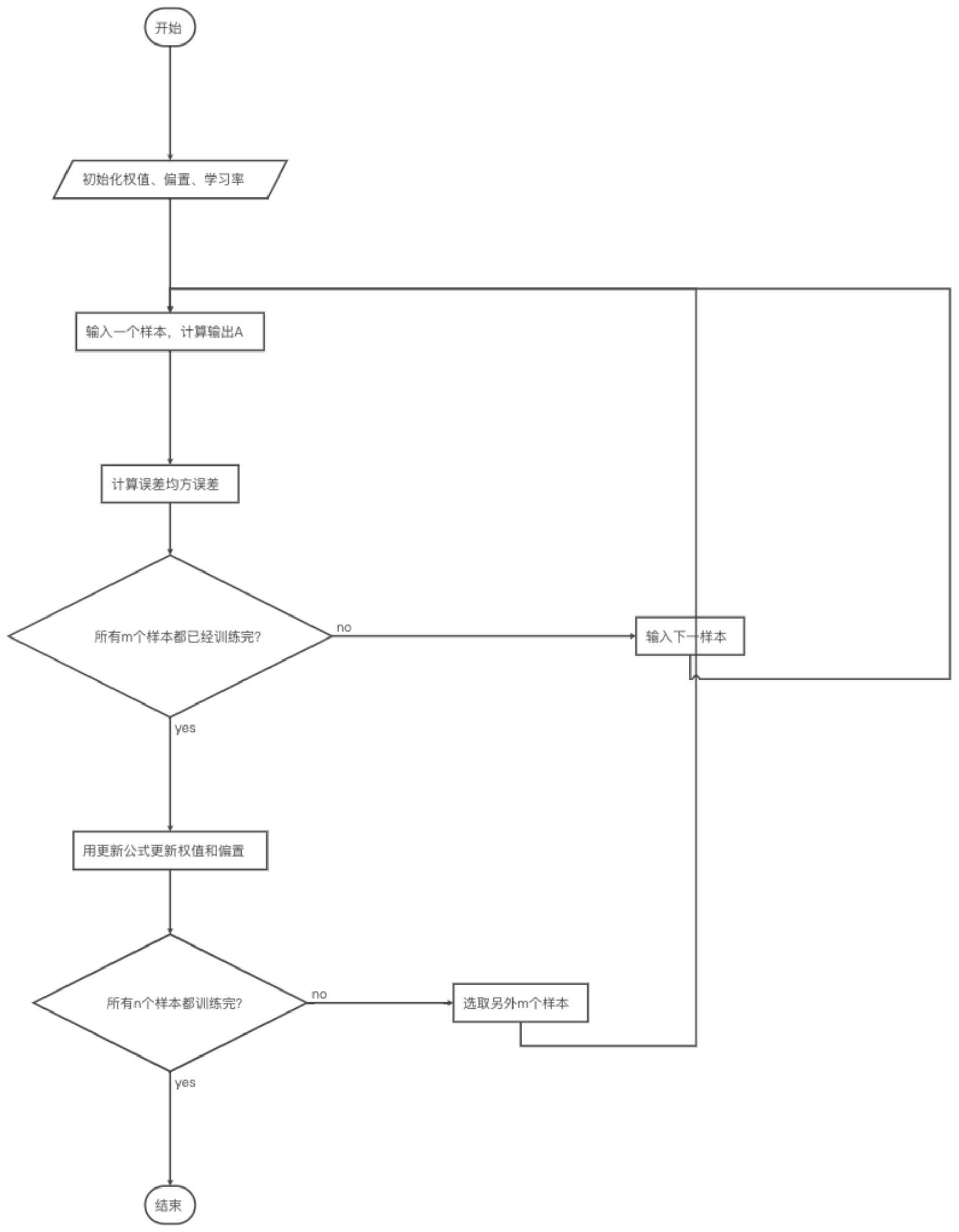
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于GBP 维度的最小梯度下降算法的推荐方法,上述推荐方法能解决现有技术中的推荐方法存在没 有办法结合基因维度进行学习,计算学习时占用大量内存,在进行优化时,震荡数值偏大, 数据批量运算时,无法进行整体梯度优化的问题,该算法在最小梯度下降算法的基础上,通 过将用户的基因(Gene),行为(Behavior),表型(Phenotypic)这三类信息称之为用户的GBP 数据,将这些数据进行标签化,进而形成以用户为基础的GBP标签;将用户的GBP信息进行标 签化后,再将内容(商品、文章、视频、图片等)信息进行标签化,进而将用户的GBP标签和内 容的标签进行算法层面的匹配;本发明中将上述算法称为基于GBP维度的mini-GD算法,对 数据进行梯度优化。根据每次迭代一定是向着最优方向前进,同时在训练样本时不占用太 多内存,分批次训练学习,保证最优解。 为实现上述发明目的,本发明采用如下的技术方案: 一种基于GBP维度的最小梯度下降算法的推荐方法,包含以下步骤: 1)根据用户的GBP数据对用户进行标签化,每个用户就都拥有了各自的GBP标签, 每个标签代表一个不同的item; 2)对内容进行手动打标签,使内容也拥有了一个或多个标签: 3)根据用户的标签和内容标签进行初步的匹配,经过用户使用、反馈和算法校准, 用户已经对一些item做出了喜好判断,喜欢其中的一部分item,不喜欢其中的另一部分; 4)通过用户过去的喜好判断,为用户形成一个通用模型,后续根据用户的实习操 作的数据反馈进行标签权重系数的调整进而优化推荐系统的推荐机制: 5)商品推荐,通过上述通用模型,就可以判断用户是否会喜欢一个新的item,最终 得到推荐结果; 其中,所述的内容为文章、视频、商品、图片等; 其中,通用模型的目标函数较难优化时,采用最小梯度下降算法进行优化; 其中,通用模型的目标函数较难优化时,采用最小梯度下降算法进行优化; 其中,所述的最小梯度下降算法是用于求出目标函数的最优解,所述目标函数为 可微分的函数;最小梯度下降算法优化的目标就是找到这个函数的最小值,通过反复求取 梯度,最后就能到达局部的最小值Mini-GD参与每一轮迭代需要所有GBP样本,对于数据中 台学习应用,其属于billion级别的训练集,计算复杂度非常高,所以需要基于Mini-GD算法 进行不断的学习和训练,找到元素之间匹配关系最小的路径进而大大缩减匹配时间提高效 率和精准度; 其中,最小梯度下降算法的具体步骤:首先做指数加权平均;假如有N天的数据, a1,a2,a3,...,aNa1,a2,a3,...,aN;概括的说,就是平均前m天的数据作为一个数据点: b0=0; bt=β*bt-1 (1-β)*atbt=β*bt-1 (1-β)*at; 5 CN 111581524 A 说 明 书 3/5 页 然后将bt计算公式中的bt-1展开,依次展开下去,会发现: bt=β*(β*bt-2 (1-β)*at-1) (1-β)*at; 然后进行偏差修正: bt=β*bt-1 (1-β)*at; bt=bt1-βt 得到修正后结果作为输入值: cal dW,dBdW,dB for each mini-GD. VdW=β*VdW (1-β)*dWVdW=β*VdW (1-β)*dW Vdb=β*Vdb (1-β)*dbVdb=β*Vdb (1-β)*db W=W-α*VdWW=W-α*VdW b=b-α*Vdb 从而解决基于GBP的批量梯度优化问题; 其中,在整个GBP大数据项目中训练集有m个样本,每个mini-batch(训练集的一个 子集)有b个样本,那么,整个训练集可以分成m/b个mini-GD;我们用ω表示一个mini-GD,用 Ωj表示第j轮迭代中所有mini-GD集合,有: Ω={ωk:k=1,2...m/b}Ω={ωk:k=1,2...m/b} 那么,mini-GD算法流程如下: repeate{repeate{foreachωkinΩ:θ:=θ-α1b∑i=1b(hθ(x(i))-y(i))x(i)} for(k=1,2...m/b)}repeate{repeate{foreachωkinΩ:θ:=θ-α1b∑i=1b(hθ(x(i))-y (i))x(i)}for(k=1,2...m/b)}; 本发明与现有技术相比具有以下优点:本发明解决了现有技术中的推荐方法存在 没有办法结合基因维度进行学习,计算学习时占用大量内存,在进行优化时,震荡数值偏 大,数据批量运算时,无法进行整体梯度优化的问题;本发明中的推荐方法的优点在实时的 解决梯度优化问题,可以使数据处理更加高效、准确,用时在数据训练学习中减少训练迭代 次数,提高学习率。 附图说明 图1为本发明中的梯度下降算法的流程图;











