
技术摘要:
本发明公开了一种基于距离加权LSSVM的过滤因子优化AdaBoost方法及系统,包括,采集复合材料损伤的声发射信号并进行特征提取,分别获得训练样本数据、测试样本数据和对应损伤类别数据;利用训练样本数据与分类平面距离构建基于加权最小二乘支持向量机的训练模型;对训练 全部
背景技术:
AdaBoost是一种迭代算法,其针对于同一个训练集训练不同的弱分类器,然后把 这些弱分类器集合起来,构成一个更强的强分类器,其算法本身是通过改变数据分布来实 现的,它根据每次训练集之中的每个样本的分类是否正确,以及上次的总体分类的准确率 来确定每个样本的权值,将修改过权值的新数据集送给下层分类器进行训练,将每次训练 得到的分类器融合起来作为最后的决策分类器。 当今用于分类的AdaBoost算法的方法主要是利用分类结果的对错减小或增大样 本的权重,以在后续迭代中使分类器更加偏重分错的样本,样本权重更新的依据和更新方 式都较为单一,生成的弱分类器多样性欠缺,且弱分类器之间错误率悬殊时大量弱分类器 并不能在最终决策中做出贡献。
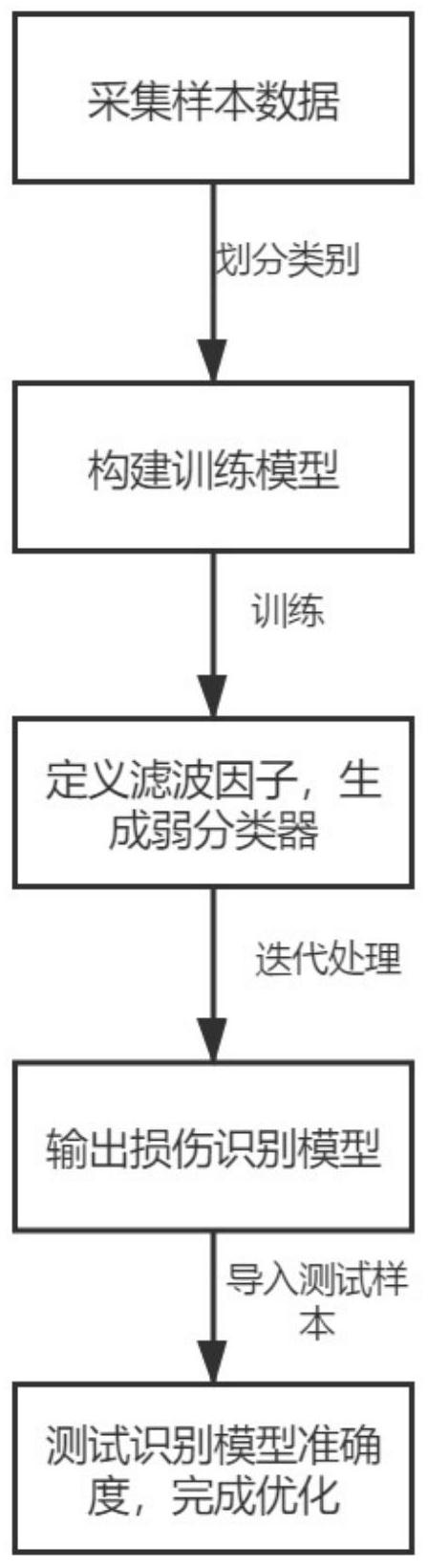
技术实现要素:
本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施 例。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部 分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。 鉴于上述现有存在的问题,提出了本发明。 因此,本发明提供了一种基于距离加权LSSVM的过滤因子优化AdaBoost方法,能够 解决多种较复杂的损失数据且相互关联而无法实现较高准确率的多分类问题,克服普通的 AdaBoost算法弱分类器多样性不足的问题。 为解决上述技术问题,本发明提供如下技术方案:包括,采集复合材料损伤的声发 射信号并进行特征提取,分别获得训练样本数据、测试样本数据和对应损伤类别数据;利用 所述训练样本数据与分类平面距离构建基于加权最小二乘支持向量机的训练模型;对所述 训练模型进行训练,利用滤波因子控制弱分类器生成的识别错误率,直至无法找到满足条 件的所述弱分类器时,停止训练,输出损伤识别模型;将所述测试样本数据导入所述损伤识 别模型内,若正确识别实际损伤类型,则完成优化;利用优化后的所述损伤识别模型识别复 合材料损伤数据并输出识别结果。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:所述满足条件包括,当所述识别错误率在不小于σ最小值的情况下,同时满 足小于0.5和小于k倍第一个所述弱分类器的所述识别错误率。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:将当前所述弱分类器生成的所述识别错误率与所述第一个弱分类器的所 5 CN 111582350 A 说 明 书 2/10 页 述识别错误率的比值定义为所述滤波因子;其中,所述滤波因子取值范围大于1且小于2。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:利用所述滤波因子还包括,当第二次分类时,同时满足所述识别错误率小 于0.5且小于所述第一个弱分类器与所述滤波因子乘积条件,则生成新的所述弱分类器;重 复生成所述弱分类器的分类步骤,直至无法找到所述满足条件的所述弱分类器,停止分类; 所述弱分类器在分类时对所述训练样本数据分别生成分类意见;整合所有生成的所述弱分 类器的所述分类意见,分别标记为相同分类意见和不同分类意见。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:所述训练模型基于所述训练样本数据与所述分类平面距离将所述训练样 本数据划分为三种类型,包括,最难型数据、较难型数据和简单型数据;所述最难型数据包 括,被赋予较大权重和距离较小的样本数据;所述较难型数据包括,被赋予中等大小权重和 距离中等的所述样本数据;所述简单型数据包括,被赋予较小权重和距离最大的所述样本 数据。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:所述加权最小二乘支持向量机利用划分的所述三种类型对相同的所述训 练样本数据得到不同的分类结果,包括, 其中,vi:样本的权重,c1、c2:参数,di:第i个样本与分类平面之间的距离。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:训练所述训练模型包括,对所述训练模型分别输入带标签的训练样本 {(x1,y1) ,…,(xN,yN)}、加权LSSVM中的惩罚因子C、核宽参数初始值σini、搜索步长σstep、最小 值σm i n、滤波因子k和权重模型参数c 1、c 2;初始化输入的数值,训练样本初始权重 加权LSSVM初始权重 i=1,…,N;所述训练模型进行迭代处理,迭代次数 t=1、2、…、T;迭代完成,输出所述损伤识别模型 其中,xi:所述训练样本数据,yi:训练样本标签,ht:所述弱分类器,αt:权重。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:所述迭代处理包括,利用所述加权LSSVM在当前样本权重分布下对所述训 练样本数据进行分类,得到所述弱分类器;所述训练模型计算所述弱分类器的所述识别错 误率 6 CN 111582350 A 说 明 书 3/10 页 其中,εt:所述识别错误率,ω ti :当前样本权重分布;当t=1时,若ε>0.5,则σ减小 一个步长σstep,重新生成所述弱分类器;当t>1时,若ε>0.5或ε>kε1,则σ减小一个步长σstep, 重新生成所述弱分类器;当σ<σmin时,设置t=T-1并结束迭代;计算所述弱分类器权重 更新训练样本权重 其中,Ct:归一化因子;计算所述训练样本数据得到所述分类平面的距离,根据新 型权重模型更新所述加权LSSVM权重;重置σ=σmin,停止迭代。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost方法的一种 优选方案,其中:计算所述训练样本数据与所述分类平面的距离包括, |d |=|wTi φ(xi) b|=|yi-εi| 其中,w为权系数向量,φ(·)为输入空间到高维空间的映射,b为偏置;根据所述 距离的大小对所述加权LSSVM设置相应的权重;所述弱分类器参考设置的所述权重大小给 出相应的分类结果。 作为本发明所述的一种基于距离加权LSSVM的过滤因子优化AdaBoost系统的一种 优选方案,其中:包括,采集模块,用于采集样本数据,收集数据信息和分类信息;数据处理 模块与所述采集模块相连接,用于接收所述样本数据进行迭代处理,其包括计算单元、调控 单元和输出管理单元,所述计算单元用于计算所述识别错误率、所述权重和所述距离,所述 调控单元用于读取所述计算单元的计算结果,调整相应的参数再反馈至所述计算单元内进 行计算,所述输出管理单元用于输出计算结果数据;分类模块连接于所述输出管理单元,用 于接收所述输出管理单元输出的结果数据并对其划分类别,归纳整合不同的数据信息;识 别模块与所述分类模块相连接,用于读取、分析、对比所述分类模块内的分类结果,输出识 别结果。 本发明的有益效果:本发明方法通过采用距离权重更新模型,根据样本与分类平 面之间的距离对样本权重进行三种类型的划分和更新,利用过滤因子对弱分类器的生成进 行控制,使得既有少量分类差异又有大量分类共识的一系列弱分类器生成,本发明方法增 强了鲁棒性,提高了分类准确率和可靠性,降低经济成本,加强了移植性。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用 的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本 领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它 的附图。其中: 图1为本发明第一个实施例所述的一种基于距离加权LSSVM的过滤因子优化 AdaBoost方法的流程示意图; 图2为本发明第一个实施例所述的一种基于距离加权LSSVM的过滤因子优化 7 CN 111582350 A 说 明 书 4/10 页 AdaBoost方法的弱分类器生成示意图; 图3为本发明第一个实施例所述的一种基于距离加权LSSVM的过滤因子优化 AdaBoost方法的训练样本数据与平面分类距离示意图; 图4为本发明第二个实施例所述的一种基于距离加权LSSVM的过滤因子优化 AdaBoost系统的模块结构分布示意图; 图5为本发明第二个实施例所述的一种基于距离加权LSSVM的过滤因子优化 AdaBoost系统的网络拓扑结构示意图。











