
技术摘要:
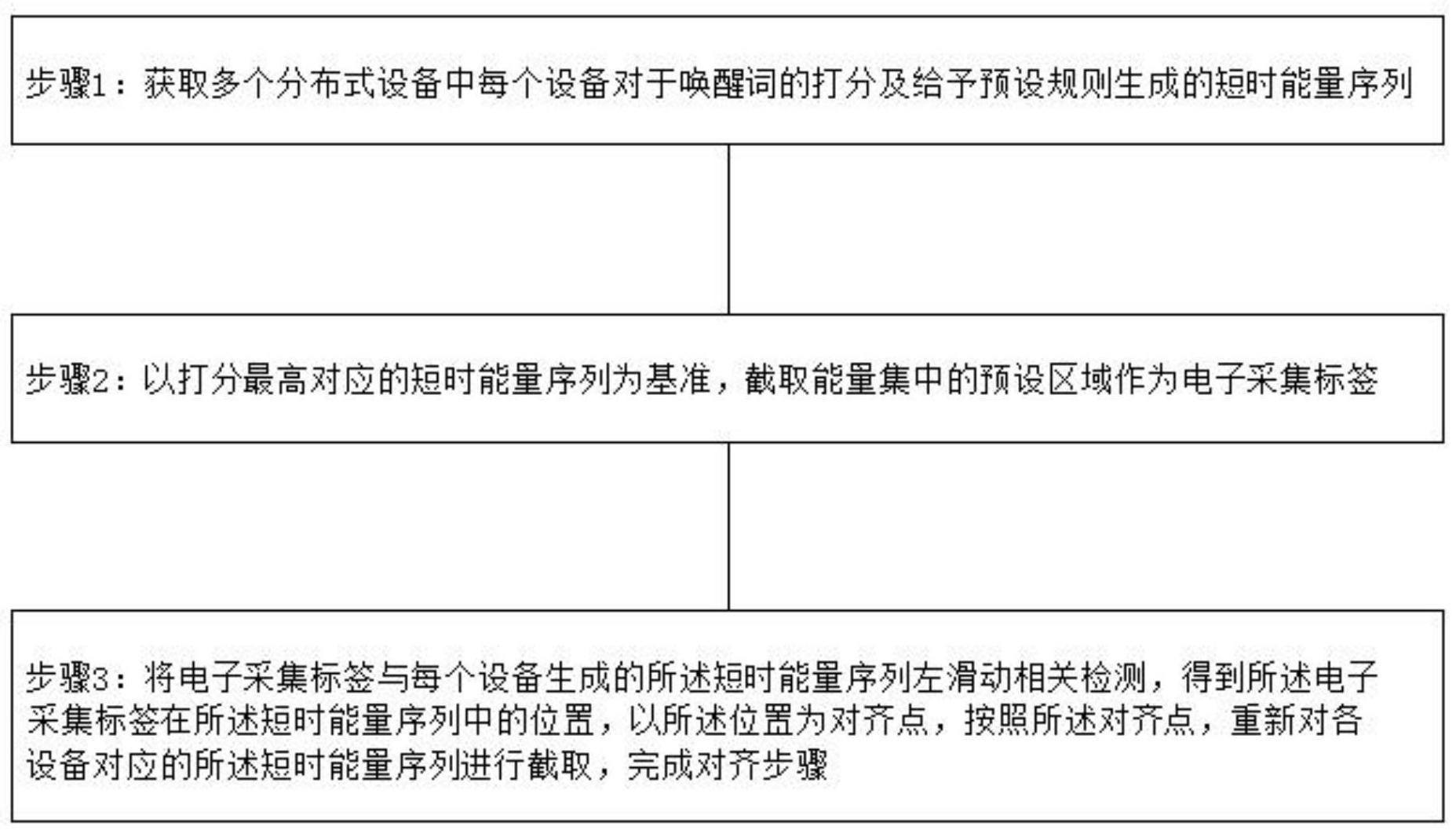
本发明提供一种分布式阵列对齐方法,解决各个分布式设备接收信号不对齐的问题。其中方法包括:获取多个分布式设备中每个设备对于唤醒词的打分及基于预设规则生成的短时能量序列;以打分最高对应的短时能量序列为基准,截取能量集中的预设区域作为电子采集标签;将电子 全部
背景技术:
在面对多个分布式设备做语音交互时,需要通过一些特征选择某个设备与人做交 互,在仅有语音信息时通常使用临近响应的原则,可通过判断设备之间能量差异来选择。 每个设备独立拾音,分别通过本地唤醒引擎得到唤醒词对应信号的时间起止点, 由于混响、噪声影响,每个设备接收的信号存在明显差异,从而造成每个设备取得的信号时 间起止点并不一致,导致计算能量时并非同一时间段信号,从而影响最终判决结果。
技术实现要素:
本发明提供一种分布式阵列对齐方法,解决各个分布式设备接收信号不对齐的问 题。 本发明实施例提供一种,包括:获取多个分布式设备中每个设备对于唤醒词的打 分及基于预设规则生成的短时能量序列; 以打分最高对应的短时能量序列为基准,截取能量集中的预设区域作为电子采集 标签; 将电子采集标签与每个设备生成的所述短时能量序列做滑动相关检测,得到所述 电子采集标签在所述短时能量序列中的位置,以所述位置为对齐点,按照所述对齐点,重新 对各个设备对应的所述短时能量序列进行截取,完成对齐步骤。 在一种可能实现的方式中,所述基于预设规则生成的短时能量序列,具体包括: 每个设备通过唤醒模块获得唤醒词对应的语音数据; 通过前端降噪模块将所述语音数据进行降噪处理; 通过唤醒打分模块对降噪处理后的所述语音数据进行打分,同时将所述语音数据 进行缓存; 当打分大于阈值时,依据唤醒模块给出的所述语音数据的起止点计算所述语音数 据的所述短时能量序列。 在一种可能实现的方式中,所述预设区域为75%~85%的短时能量序列的部分。 在一种可能实现的方式中,所述将电子采集标签与每个设备生成的所述短时能量 序列做滑动相关检测,得到所述电子采集标签在所述短时能量序列中的位置,具体包括: 将所述电子采集标签的起始位与所述短时能量序列中的第一位能量值对应;将所 述电子采集标签的后续的每一位能量值与所述短时能量序列中的第一位后续的每一位能 量值进行一一对应,确定该对应关系的初始参考值; 然后,依次将所述电子采集标签的起始位与所述短时能量序列中的第二位能量 值、第三位能量值直至最后一位能量值进行对应,确定多个所述初始参考值; 比较确定的多个所述初始参考值,取最大的所述参考值时的对应关系为所述电子 4 CN 111596882 A 说 明 书 2/7 页 采集标签在所述短时能量序列中的位置。 在一种可能实现的方式中,所述将所述电子采集标签的起始位与所述短时能量序 列中的第一位能量值对应;将所述电子采集标签的后续的每一位能量值与所述短时能量序 列中的第一位后续的每一位能量值进行一一对应,确定该对应关系的初始参考值,具体为: 首先,将所述电子采集标签的第一位能量值与所述短时能量序列中的第一位能量 值进行比对;依次将所述电子采集标签的下一位能量值与所述短时能量序列中的下一位能 量值进行比对;当所述电子采集标签的所有能量值比对完成后,统计比对符合的个数作为 所述初始参考值。 在一种可能实现的方式中,通过唤醒打分模块对降噪处理后的所述语音数据进行 打分中,打分的具体操作如下: 提取所述语音数据的特征序列;所述特征序列包括:所述语音数据的每一帧的特 征向量; 将每一个所述特征向量分别带入到事先训练好的唤醒词模型中进行打分,获得所 述特征向量的分值;所述唤醒词模型为混合高斯模型; 将所述特征序列中的各个所述特征向量的分值相加作为所述语音数据的分值; 其中,将所述特征向量o=(o1 ,o2,···,oi,···,on)带入到事先训练好的唤 醒词模型中进行打分的计算公式为: 其中,log(P(O))为所述特征向量的分值,j表示为所述唤醒词模型的第j个参数向 量,m表示所述唤醒词模型的所述参数向量的个数,所述唤醒词模型的平均向量为μ=(μ1 , μ2,···,μi,···,μn),cj为对应所述第j个参数向量的常数。 在一种可能实现的方式中,通过唤醒打分模块对降噪处理后的所述语音数据进行 打分中,打分的具体操作如下: 提取所述语音数据中的特征,所述特征包括各个字节之间的停顿时间、各个字节 的能量幅值、各个字节的起止时间值; 基于所述各个字节之间的停顿时间与各个字节之间对应的预设的字节停顿时间, 计算出第一分值A1;公式如下: 其中,ti表示第i个字节和第i 1个字节之间的停顿时间;Ti表示第i个字节和第i 1 个字节之间对应的预设的字节停顿时间;ai表示第i个字节和第i 1个字节之间对应的预设 的字节停顿时间所对应的权重;n表示所述语音数据中的字节的个数; 基于所述各个字节的能量幅值与各个字节对应的预设的能量幅值,计算出第二分 值A2;公式如下: 5 CN 111596882 A 说 明 书 3/7 页 其中,mi表示第i个字节的能量幅值;Mi表示第i个字节对应的预设的能量幅值;bi 表示第i个字节对应的预设的能量幅值所对应的权重; 基于所述各个字节的起止时间值与各个字节对应的预设的起止时间值,计算出第 三分值A3;公式如下: 其中,di表示第i个字节的起止时间值;Di表示第i个字节对应的预设的起止时间 值;ci表示第i个字节对应的预设的起止时间值所对应的权重; 基于所述第一分值、所述第二分值、所述第三分值及各个分值的权重,计算出所述 语音数据的最终分值A终;公式如下: A终=αA1 βA2 γA3; 其中,α、β、γ分别为所述第一分值的权重、所述第二分值的权重、所述第三分值的 权重。 在一种可能实现的方式中,计算所述语音数据的所述短时能量序列具体包括: 将所述语音数据按每隔一预设时间截取为一个短时数据的方式获得多个短时数 据,分别计算各个所述短时数据的能量;将各个所述短时数据的能量组成数组后形成所述 短时能量序列。 本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明 书、权利要求书、以及附图中所特别指出的结构来实现和获得。 下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。 附图说明 附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实 施例一起用于解释本发明,并不构成对本发明的限制。在附图中: 图1为本发明实施例中一种分布式阵列对齐方法流程图。











