
技术摘要:
本发明公开了一种多通道有源降噪头靠的降噪方法,通过采集计算模块得到耳廓空间位置信息,并选定耳廓上一点坐标为虚拟误差传声器的空间坐标,通过已知空间坐标的物理传声器和次级声源,计算得到从次级声源和物理传声器到虚拟误差传声器的时延值,使用离线建模的方式获 全部
背景技术:
噪声污染是一种对人体影响较大的环境污染,当人们长期在高噪声环境中时,工 作效率会降低,人的听力和身心健康也会受到影响。尤其是对于汽车、高铁、轮船、和飞机等 运载交通工具,舱室区域的噪声严重影响司乘人员乘坐时的舒适性,舱室噪声中的低频噪 声成分很难控制,被动噪声控制对材料的尺寸、体积有较高要求,在舱室中难以满足。有源 噪声控制(Active noise control,ANC)技术具有体积小、低频噪声控制效果好的特点。有 源噪声控制技术基于惠更斯波形叠加原理,因此对舱室噪声进行全局控制难以满足,一般 采用局部有源噪声控制的方法降低乘客头部区域的噪声。在无遮挡的条件要求下,有源头 靠、头枕(Active headrest)是局部空间有源噪声控制的成功应用之一。 专利CN201620075679.5和CN201810463634.9分别公开了一种有源降噪头枕,将噪 声控制系统一体化集成在头枕中,控制装置根据环境噪声和校正噪声控制扬声器产生控制 声波,降低使用者头部活动区域的低频噪声,提升声学舒适性。但在一般的有源噪声控制系 统中,误差传声器应尽量靠近人耳布放,次级源根据应用场景布放于人耳周围,这样才能最 终在误差传声器附近产生有源静音区。通常情况下,静音区的大小与噪声波长相关,单通道 有源降噪系统产生的静区直径一般小于1/10波长,为了保证降噪效果,误差传声器应尽可 能靠近人耳,这就造成了误差传声器与人头移动的冲突。在实际使用过程中,司乘人员不可 能一直紧贴着头靠,当人头移动时,有源降噪头靠的降噪效果就大打折扣,甚至失去效果。 为解决人头移动的影响,专利201910998134.X引入虚拟传声器技术,通过目标区 域外的物理传声器拾取声信号对人耳附近虚拟传声器处(原误差传声器位置)的声压进行 估计和控制,进而转移有源静区至人耳附近来提高有源降噪系统在人头移动时的鲁棒性。 但该专利仅仅提出了当人头前后左右移动和转动时的虚拟传声器与物理传声器之前的传 递路径计算方法,采用移动路径估计的方法计算出使人头位于不同位置时系统的噪声残余 最大值最小化的最优虚拟次级路径传递函数估计值,当复杂运动时计算量急剧增大。该方 法还将人头建模为一刚性球,双耳在刚性球表面,位于通过刚性球中心的直径上,与实际情 况并不相符,无法取得真实的良好控制效果。 司乘人员在乘坐过程中,头部的运动是由上下、左右、前后移动和左右转动等多种 方式组合而成的复杂运动,虚拟传声器与物理传声器之间的映射关系是动态变化的。因此 需要提供一种能够直接获取虚拟传声器传递函数的方法,提供给有源降噪头靠系统以解决 以上问题。
技术实现要素:
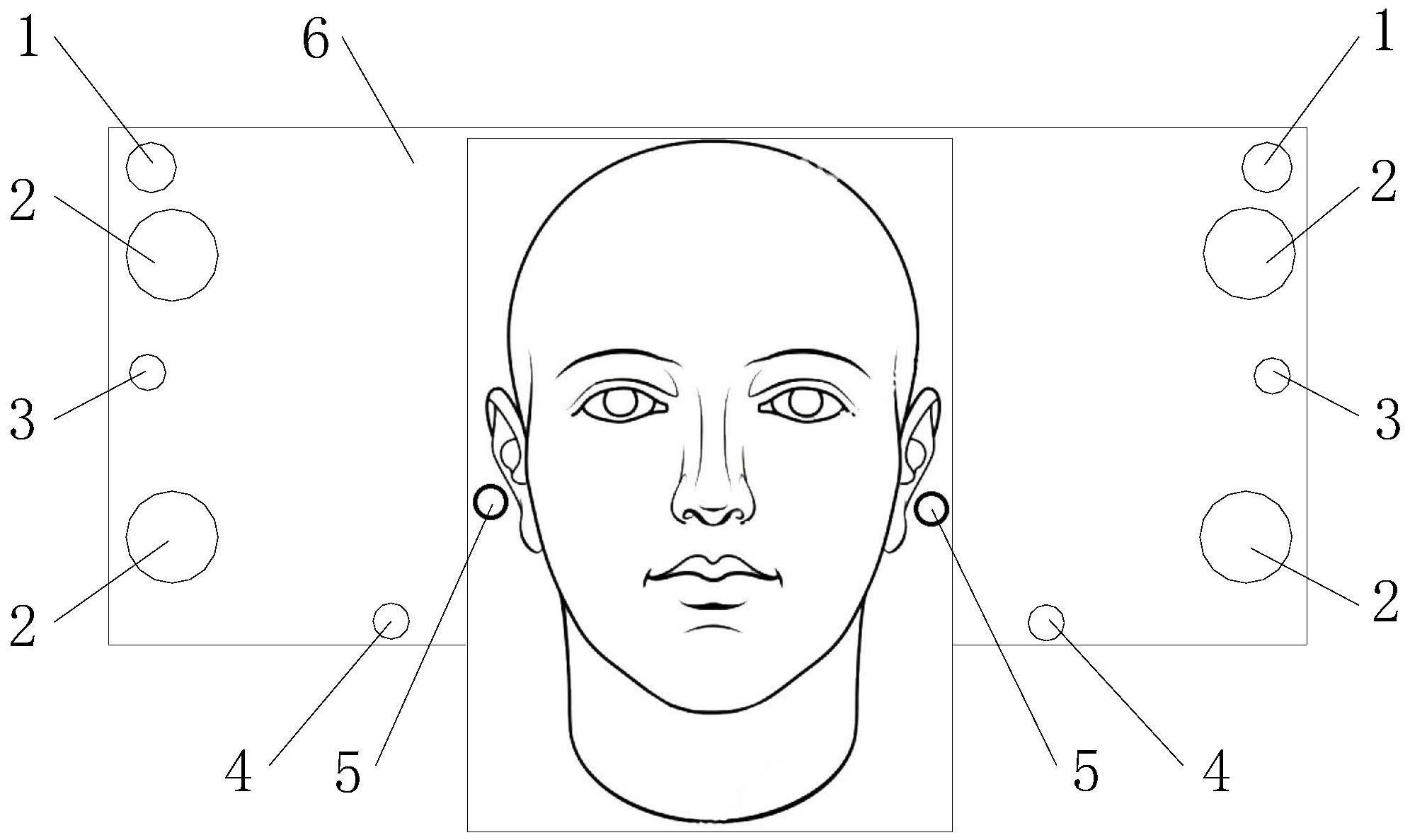
本发明的目的是提供一种多通道有源降噪头靠的降噪方法,在人耳移动过程中, 能够精确的得到虚拟误差传声器的位置,经过简单计算即可得到有源降噪系统所需的虚拟 5 CN 111583896 A 说 明 书 2/7 页 次级路径传递函数矩阵Gvu和初级声场传递函数矩阵M,系统响应快,降噪效果好。 为达到上述目的,本发明采用的技术方案是: 一种多通道有源降噪头靠的降噪方法,包括以下步骤: (1)通过装载在头靠上的采集计算模块得到耳廓空间位置信息; (2)选定耳廓上某一特征点作为抓取点,将所述抓取点的空间坐标定义为虚拟误 差传声器的空间坐标; (3)通过装载在所述头靠上的已知空间坐标的物理传声器和次级声源,计算得到 从所述次级声源和所述物理传声器到所述虚拟误差传声器的时延值,所述物理传声器包括 物理参考传声器和物理误差传声器;所述次级声源至所述虚拟误差传声器的虚拟次级路径 传递函数矩阵为Gvu,所述物理误差传声器与所述虚拟误差传声器之间的初级声场传递函 数矩阵为M,由于所述次级声源与所述物理误差传声器位置固定,使用离线建模的方式获得 固定的所述次级声源至固定的所述物理传声器的物理次级路径传递函数矩阵Gpu; (4)所述物理参考传声器采集噪声产生参考信号,所述物理误差传声器采集噪声 产生物理误差信号ep;将所述参考信号和所述物理误差信号传递给自适应控制器,所述自 适应控制器根据传递函数矩阵Gvu、M和Gpu以及所述次级声源的强度u(n)计算得到虚拟误 差信号ev,所述自适应控制器根据所述参考信号与所述虚拟误差信号进行计算,产生消声 信号,并传递给所述次级声源;所述次级声源接收所述自适应控制器传来的所述消声信号 并发出声音,对原有噪声进行抵消降噪,使所述虚拟误差传声器处的声压幅值平方最小。 优选地,在步骤(1)中,所述采集计算模块包括RGB-D相机、卷积神经网络结构模 型;所述卷积神经网络结构模型用于识别人耳耳廓;所述RGB-D相机包括彩色传声器和深度 传声器,根据两者之间的外参构建彩色图像数据与深度数据之间的映射关系,以得到以像 素坐标[u,v]形式存在的图像,利用内参进行坐标系变化以得到空间坐标P(x,y,z)。 更优选地,像素平面中P′的像素坐标为[u,v],根据所述RGB-D相机的内参K 和像 素P′[u,v]对应的深度Z由公式(1)得出空间坐标P(x,y,z); 其中,K矩阵为RGB-D相机的内参数矩阵,P为P′的三维空间坐标。 优选地,在步骤(2)中,所述抓取点为耳廓的三角窝角点或耳甲腔边缘的角点。 优选地,所述头靠上对应每一侧人耳均设有所述采集计算模块、所述物理传声器 和所述次级声源。 优选地,所述多通道有源降噪头靠的降噪方法采用多通道自适应前馈控制系统, 使用可移动的虚拟误差传声器作为误差传声器,建立模型如下: 设控制系统有L个次级声源、Mp个物理传声器、Mv个移动虚拟误差传声器;移动虚拟 误差传声器的时变位置包含在大小为3×Mv的矩阵xv(n)中,定义为: 其中每个移动虚拟位置 由相对于一个参考系的三个空间坐标定义: 6 CN 111583896 A 说 明 书 3/7 页 计算模型需要在每个时间步长都知道Mv个移动虚拟误差传声器的空间坐标 xv (n),通过步骤(2)得到移动虚拟误差传声器的空间坐标; 在移动的虚拟位置xv(n)上计算虚拟误差信号的估计值 , 在移动虚拟传感算法中,首先需要获得 个空间坐标固定的虚拟误差传声器 的虚拟误差信号的估计值 设移动虚拟误差传声器的空间虚拟位置 xv(n)被限制在 一个有限的三维区域中,此时空间位置固定的虚拟误差传声器 也就位于所述三维区域 中, 个空间坐标固定的虚拟误差传声器位置的向量由式(4)给出; 则每个空间坐标固定的虚拟位置 由相对于一个参考系的三个空间坐标定义: 空间位置固定的虚拟误差传声器 的误差信号估计值 由物理误差传声器信 号与次级声源强度传递函数得到: 其中,ep(n)为物理误差传声器的物理误差信号, 是阶数为Mp×L的次级声源到 物理误差传声器的传递函数矩阵, 是阶数为 的次级声源到虚拟误差传声器的传 递函数矩阵,u(n)为次级声源的强度矢量; 将两个次级通道传递函数矩阵建模成两个FIR或两个IIR滤波器;在系统辨识的初 级阶段,将阶数为 的从空间坐标固定的物理传声器到虚拟误差传声器之间的次级 通道传递函数矩阵 建模成一个FIR或IIR滤波器;Mp个物理误差传声器的初级噪声信号 为: 空间位置固定的虚拟误差传声器 的初级噪声估计值为: 由此空间位置固定的虚拟误差传声器 的总的虚拟误差信号的估计值 为: 根据所述移动虚拟传感算法,通过对空间坐标固定的虚拟误差传声器 的虚拟误 差信号 进行空间插值,可以获得在移动的虚拟位置上xv(n)的虚拟误差信号的估计值 7 CN 111583896 A 说 明 书 4/7 页 。 更优选地,所述自适应控制器根据所述参考信号与所述虚拟误差信号,采用自适 应有源控制算法进行计算,产生所述消声信号。 更进一步优选地,所述自适应有源控制算法为多通道Fx-LMS算法。 由于上述技术方案的运用,本发明与现有技术相比具有下列优点:本发明一种多 通道有源降噪头靠的降噪方法,具有以下优点: (1)采用多通道有源降噪系统,经合理设计可扩大静音区的有效范围,提升降噪性 能; (2)在人耳移动过程中,通过采集计算模块能够直接提取耳廓空间坐标信息,以精 确的得到虚拟误差传声器的位置,用硬件的测量精度来保证降噪控制效果,提升系统鲁棒 性; (3)使用直接获取的虚拟误差传声器空间坐标,经过简单计算即可得到有源降噪 系统所需的虚拟次级路径传递函数矩阵Gvu和初级声场传递函数矩阵M,系统响应快,降噪 效果好。 附图说明 附图1为多通道有源降噪头靠的结构示意图一; 附图2为多通道有源降噪头靠的结构示意图二; 附图3为声压信号的时间历程图; 附图4为功率谱密度图。 附图5为移动虚拟传感算法框图。 其中:1、RGB-D相机;2、次级声源;3、物理参考传声器;4、物理误差传声器;5、虚拟误差 传声器;6、头靠;7、数据处理终端。











