
技术摘要:
本发明公开了一种基于上下文注意力机制的单目无监督深度估计方法,属于图像处理和计算机视觉领域。本发明采用基于混合几何增强损失函数和上下文注意力机制的深度估计方法,采用基于卷积神经网络的深度估计子网络、边缘子网络和相机姿位估计子网络得到高质量的深度图。 全部
背景技术:
现阶段,深度估计作为计算机视觉领域的一项基本研究任务,在目标检测、自动驾 驶以及同时定位与地图构建等领域具有广泛的应用。深度估计尤其是单目深度估计在没有 几何约束和其他先验知识的情况下,从单张图片预测深度图是一个极度不适定问题。到目 前为止,基于深度学习的单目深度估计方法主要分为两类:有监督方法和无监督方法。尽管 有监督方法能够得到较好的深度估计结果,但是其需要大量的真实深度数据作为监督信 息,而这些真实深度数据不易获取。相对地,无监督方法则提出将深度估计问题转化为视点 合成问题,从而避免在训练过程中使用真实深度数据作为监督信息。根据训练数据的不同, 无监督方法又可进一步细分为基于立体匹配对和基于单目视频的深度估计方法。其中,基 于立体匹配对的无监督方法在训练过程中,通过建立左右图像之间的光度损失 (photometric loss)来指导整个网络的参数更新。然而,用来训练的立体图片对通常很难 获得并且需要事先校正,从而限制了这类方法在实际中的应用。基于单目视频的无监督方 法则提出在训练过程中使用单目图片序列即单目视频,通过建立相邻两帧之间的光度损失 来预测深度图(T.Zhou,M.Brown,N.Snavely,D.G.Lowe,Unsupervised learning of depth and ego-motion from video,in:IEEE CVPR,2017,pp.1–7.)。由于视频相邻帧之间的相机 位姿是未知的,因此,在训练时需要同时估计深度和相机位姿。目前的无监督损失函数虽然 形式简单,但其缺点是不能保证深度边缘的锐度和深度图精细结构的完整,尤其是在遮挡 和低纹理区域会产生质量较差的深度估计图。另外,目前基于深度学习的单目深度估计方 法通常无法获得远距离(long-range)特征之间的相关性,从而无法得到更好的特征表达, 导致估计的深度图存在细节丢失等问题。
技术实现要素:
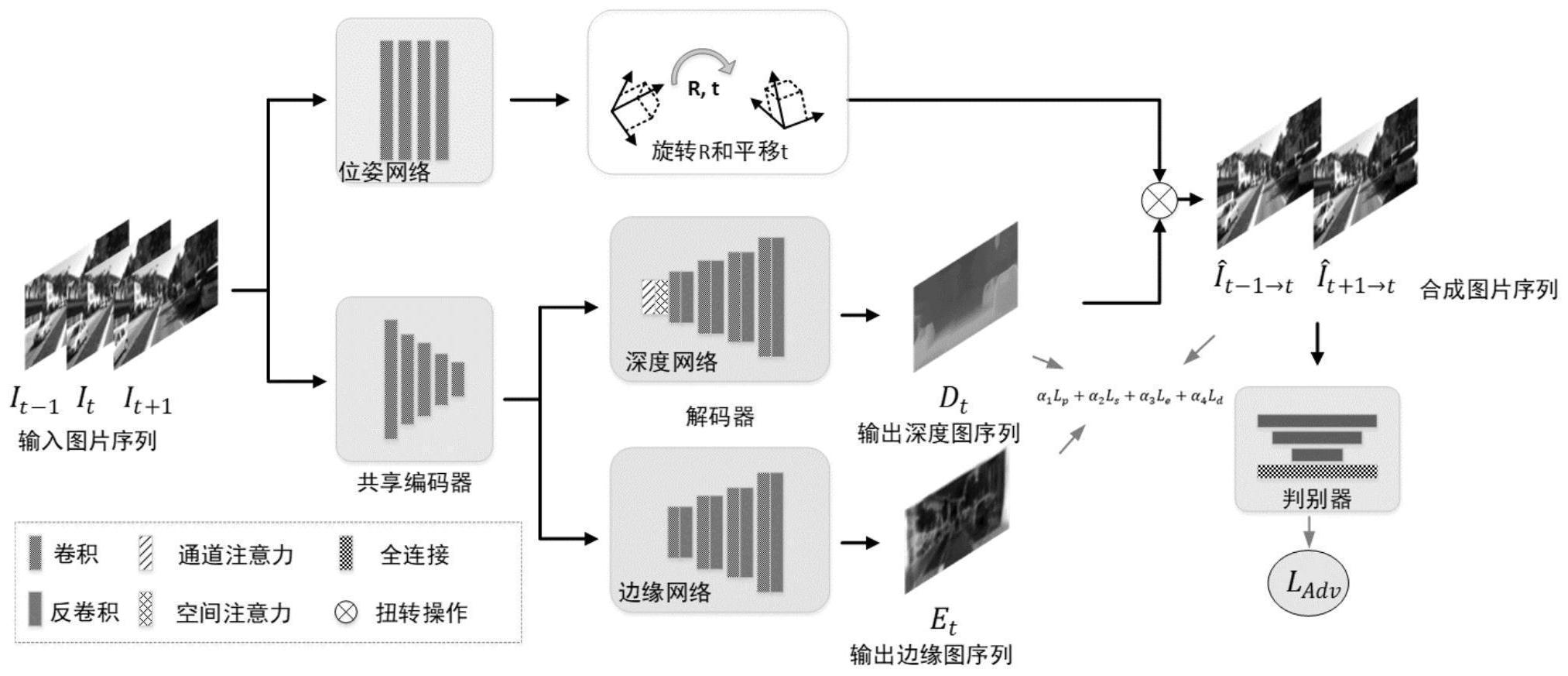
本发明旨在克服现有技术的不足,提供了一种基于上下文注意力机制的单目无监 督深度估计方法,设计了一个基于卷积神经网络进行高质量深度预测的框架,该框架包括 四个部分:深度估计子网络,边缘估计子网络,相机位姿估计子网络和判别器,并提出上下 文注意力机制模块来有效获取特征,以及构建混合几何增强损失函数训练整个框架,以获 得高质量的深度信息。 本发明的具体技术方案为,一种基于上下文注意力机制的单目无监督深度估计方 法,包括如下步骤: 1)准备初始数据:初始数据包括用来训练的单目视频序列和用来测试的单幅图片 或序列; 5 CN 111739078 A 说 明 书 2/5 页 2)深度估计子网络和边缘子网络的搭建以及上下文注意力机制的构建: 2-1)利用编码器-解码器结构,将包含残差结构的残差网络作为编码器的主体,用 于把输入的彩色图转换为特征图;深度估计子网络与边缘子网络共享编码器,但拥有各自 的解码器便于输出各自的特征;解码器中包含反卷积层用于上采样特征图并将特征图转换 为深度图或者边缘图; 2-2)将上下文注意力机制加入到深度估计子网络的解码器中; 3)相机位姿子网络的搭建: 相机位姿子网络包含一个平均池化层和五个以上卷积层,且除最后一个卷积层 外,其他卷积层都采用了批标准化(batch normalization,BN)和ReLU(Rectified Linear Unit)激活函数; 4)判别器结构的搭建:判别器结构包含五个以上的卷积层,每个卷积层都采用了 批标准化和LeakyReLU激活函数,以及最后的全连接层; 5)构建基于混合几何增强的损失函数; 6)将步骤(2)、步骤(3)、步骤(4)得到的卷积神经网络进行联合训练,监督方式采 用步骤5)中构建的基于混合几何增强的损失函数逐步迭代优化网络参数;当训练完毕,即 可以利用训练好的模型在测试集上进行测试,得到相应输入图片的输出结果。 进一步地,上述步骤2-2)中上下文注意力机制的构建,具体包括以下步骤: 将上下文注意力机制加入到深度估计网络的解码器的最前端;上下文注意力机制 如图2所示,前层编码器网络得到的特征图 其中H,W,C分别代表高度、宽度、通 道数;首先将A变形为 N=H×W,然后对B及其转置矩阵BT做乘法运算,结果经过 softmax激活函数运算可以得到空间注意力图 或通道注意力图 即S= softmax(BBT)或S=softmax(BTB);接下来,对S和B做矩阵乘法并变形为 最后 将原特征图A与U逐像素地加和得到最终的特征输出Aa。 本发明的有益效果是: 本发明基于深度神经网络,搭建一个基于50层残差网络的深度估计子网络和边缘 子网络,得到初步的深度图与边缘信息图;在此基础上,利用相机位姿估计网络得到的相机 位姿信息与深度图通过扭转函数(warping function)得到合成的相邻帧彩色图,利用混合 几何增强损失函数优化,将优化的合成图通过判别器判别与真实彩色图的差异,通过对抗 损失函数优化差异,当差异足够小时,便可得到高质量的估计深度图。该发明具有以下特 点: 1、系统容易构建,使用卷积神经网络即可以端到端的方式从单目视频得到对应的 高质量的深度图;程序框架易于实现;算法运行速度快。 2、本发明利用无监督方法来求解深度信息,避免了有监督方法中真实数据难以获 取的问题。 3、本发明利用单目视频即单目图片序列求解深度信息,避免了使用立体图片对解 决单目图片深度信息时立体图片对难以获取的问题。 4、本发明设计的上下文注意力机制和混合几何损失函数能够有效提升性能。 5、本发明具有很好的可扩展性,通过结合不同的单目相机实现算法,能够实现更 6 CN 111739078 A 说 明 书 3/5 页 加精确的深度估计。 附图说明 图1是本发明提出的卷积神经网络结构图。 图2是上下文注意力机制结构图。 图3是本发明的实验结果图。不同数据库中(a)为输入彩色图,(b)为真实的深度 图;(c)为本发明的输出深度图结果。











