
技术摘要:
本发明涉及一种深度卷积神经网络的剪枝方法、计算机设备及应用方法,包括:(1)以层为单位,执行卷积核谱聚类算法;(2)进行层内的卷积核剪枝,动态计算本轮谱聚类剪枝率,剪掉非聚类中心的卷积核,微调一定的轮数以恢复精度;(3)以全局为单位,计算卷积核重要性; 全部
背景技术:
近年来,随着深度学习的快速发展,其在图像分类、目标检测、语义分割等计算机 视觉相关领域,以及语音识别、机器翻译、语义情感分析等自然语言处理相关领域都取得了 重大进展。深度学习中的核心技术正是深度卷积神经网络。然而,在深度卷积神经网络的性 能不断突破的情况下,随之而来的是不断增长的网络宽度和深度。如从8层AlexNet的0.61 亿个参数,7.29亿的浮点型运算次数,到16层VGG-16的1.38亿个网络参数,155亿的浮点型 运算次数,使得计算开销与存储开销越来越大。如此复杂的网络无法在诸如智能手机,开发 板等嵌入式设备上运行。 现有技术中解决上述计算开销和存储开销的问题有两个主要的方向: 一个方向是设计专门的神经网络处理芯片,通过专门的硬件结构来降低神经网络运行 的开销,实现模型的加速,这种方法属于硬件层面的方法,如近几年智能手机上开始兴起的 嵌入式神经网络处理器(Neural Network Processing Units,NPU)等。 另一个方向是对现有模型结构进行简化,实现对模型的压缩与加速,这种方法属 于软件层面的方法,与通过特定硬件加速的方法并不矛盾,而是相辅相成的关系。 针对软件层面的简化,当前的压缩和加速方法均采用剪枝方法,具体地,基于参数 剪枝的方法是在预训练好的模型上,通过删除冗余权重,从而减少网络的参数量。根据是否 一次性删除整个卷积核为依据,参数剪枝又可以细分为结构化剪枝与非结构化剪枝。结构 化剪枝就是一次性删除整个卷积核的参数,而非结构化剪枝删除的是卷积核内的参数。 另外,业内人士提出了最优化脑损失(Optimal Brain Damage,OBD)算法,模仿生 物大脑的学习过程,通过突触删减减少连接个数,同时保证模型准确率维持在最小损失的 状态。另一些人提出了一种基于低权重连接修剪的剪枝策略,通过训练、删除连接、重训练 三个阶段识别低权重的参数并修剪以及恢复网络精度,该方法只删除卷积核内部的权重, 会导致卷积核的稀疏化,属于非结构化剪枝的方法。还有一些人利用范数来度量卷积核的 重要性,以此为标准删除重要性低的卷积核,这种方法直接删除整个卷积核,属于结构化剪 枝的方法。 可以看出,非结构化剪枝只是将卷积核内冗余的参数置零,带来卷积核的核内稀 疏化,减少参数数量,从而使网络模型的存储大小降低,但并没有改变网络结构,若要实现 网络的训练或推理加速,需要特定的硬件支持,如果运行在通用平台(如GPU、CPU)上则不能 实现真正网络加速。因此非结构化剪枝在通用平台上只能实现降低网络模型的存储大小 (网络压缩),而不能降低网络的计算开销(网络加速)。 为此,如何有效降低深度卷积神经网络的存储大小,同时可以降低深度卷积神经 网络的计算开销,实现在通用硬件平台上实现网络加速成为当前亟需解决的技术问题。 6 CN 111723915 A 说 明 书 2/18 页
技术实现要素:
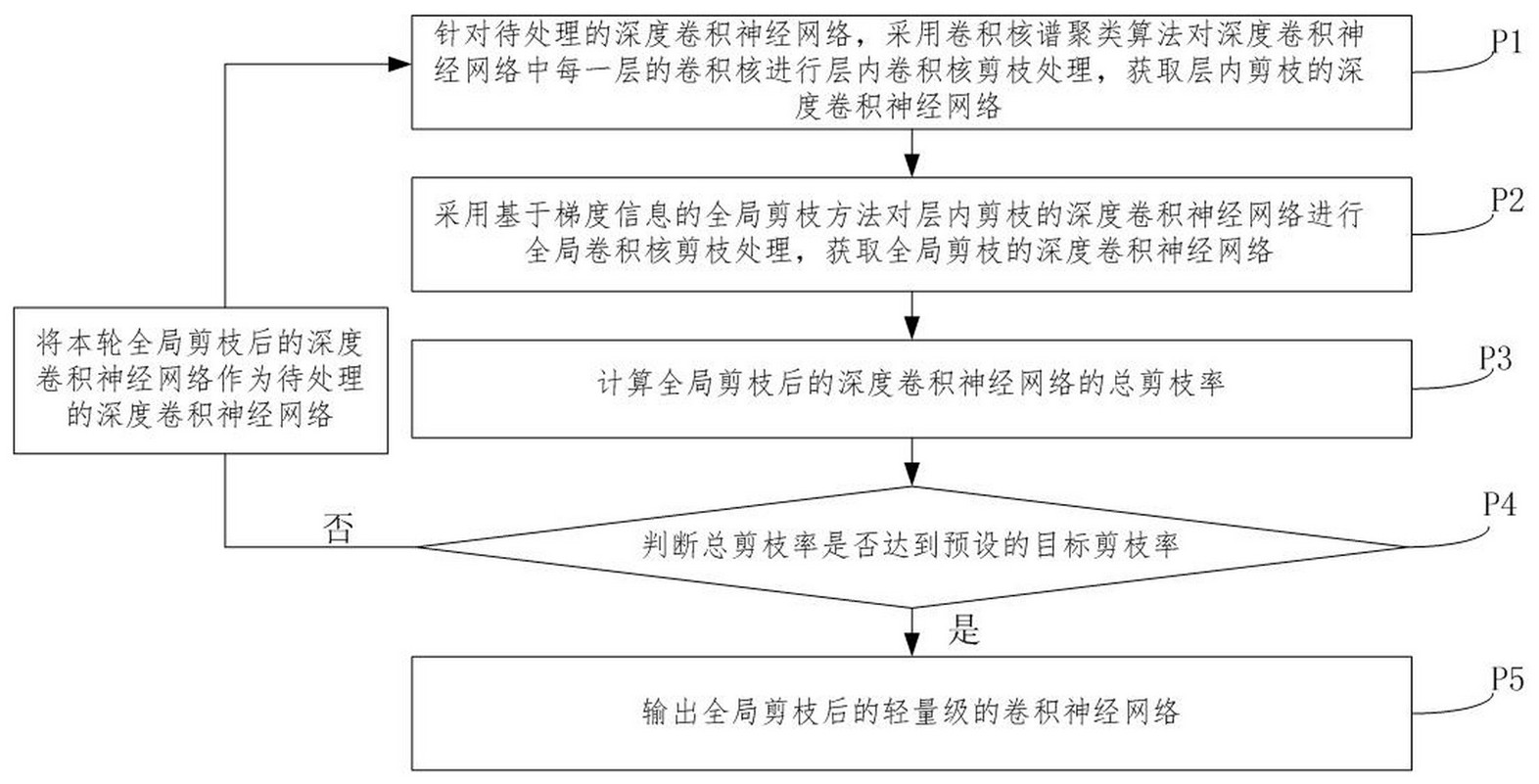
鉴于现有技术的上述缺点、不足,本发明提供一种深度卷积神经网络的剪枝方法, 其解决了现有技术中非结构化剪枝方法无法在通用硬件平台上实现网络加速的技术问题。 为了达到上述目的,本发明采用的主要技术方案包括: 第一方面,本发明实施例提供一种深度卷积神经网络的剪枝方法,包括: 针对待处理的深度卷积神经网络,采用卷积核谱聚类算法对深度卷积神经网络中每一 层的卷积核进行层内卷积核剪枝处理,获取层内剪枝的深度卷积神经网络; 采用基于梯度信息的全局剪枝方法对层内剪枝的深度卷积神经网络进行全局卷积核 剪枝处理,获取全局剪枝的深度卷积神经网络; 计算全局剪枝的深度卷积神经网络的总剪枝率; 判断所述总剪枝率是否达到预设的目标剪枝率; 若未达到,则针对全局剪枝的深度卷积神经网络,重复上述层内剪枝处理和全局剪枝 处理的步骤,直至当前轮剪枝后得到的深度卷积神经网络的总剪枝率达到目标剪枝率; 其中,所述层内卷积核剪枝处理和全局剪枝核剪枝处理均为通过结构化剪枝的方式删 除深度卷积神经网络的冗余卷积核。 可选地,针对待处理的深度卷积神经网络,初始剪枝时,定义参数如下: ; x为常数,i为迭代次数, ,表示第i轮循环 时,执行层内剪枝步骤前后的联合利用率的变化量;s为层内剪枝标识 第i轮循环时,层内剪枝的剪枝率为 ; ,表示第i轮循环时,执行全局剪枝步骤 前后的联合利用率的变化量;g为全局剪枝的标识 第i轮循环时,全局剪枝的剪枝率为 ; 联合利用率 表示一个网络计算量利用率与参数量利用率之和。 可选地,所述采用卷积核谱聚类算法对深度卷积神经网络中每一层的卷积核进行 层内卷积核剪枝处理,获取层内剪枝的深度卷积神经网络,包括: A01、获取进行第i轮层内剪枝处理的谱聚类剪枝率 ; A02、针对第i轮待处理的深度卷积神经网络,对该深度卷积神经网络中的每一层执行 卷积核谱聚类算法,将深度卷积神经网络中的卷积核聚类为不同的类别,根据谱聚类剪枝 率 进行本轮层内的卷积核剪枝处理; 其中,i=1时,初始化的层内剪枝的剪枝率为给定数值,待处理的深度卷积神经网络是 给定的网络结构; A03、微调剪掉非聚类中心的卷积核的网络中一定的轮数以恢复该网络的精度,获得层 内剪枝的深度卷积神经网络。 7 CN 111723915 A 说 明 书 3/18 页 可选地,还包括: A04、计算层内剪枝对应的联合利用率 ,以及层内剪枝对应的联合利用率的 变化量 , ; 其中,联合利用率为层内剪枝的深度卷积神经网络的计算量利用率与参数量利用率之 和; ; ; ; acc为当前网络结构的准确率,FLOPs为当前网络结构的计算量, 为当前 网络结构未剪枝前的网络结构的计算量, 为当前网络的计算量利用率; Params为当前网络结构的参数量, 为当前网络结构未剪枝前的网络 结构的参数量, 为当前网络的参数量利用率; 联合利用率的变化量为第i轮剪枝前和第i轮剪枝后的联合利用率的变化量; ; ; 为第i轮聚类剪枝后的联合利用率, 为第i轮全局剪枝后的利用率。 可选地,A02包括: A02-1、在执行层内谱聚类剪枝算法的处理设备获取第一信息,所述第一信息包括:待 处理的深度卷积神经网络中待处理层的卷积核个数 ,剪枝率 ;其中,i=1时,初始化 的 和 为给定数值,在中间迭代时, 和 为根据上一次剪枝后的深度卷积神 经网络的信息确定的; A02-2、处理设备基于层内谱聚类剪枝算法对第一信息进行剪枝处理; 具体地,A02-2-1、针对每一层,将每个卷积核展开为一维向量得到待聚类的卷积核集 合 ; A 0 2 - 2 - 2 、根据卷积核个数 ,剪枝率 计算当前层的聚 类类别数 ; A02-2-3、指定邻接矩阵的构建方法为全连接法,切图方式为NCut切图,调用卷积核谱 聚类算法进行处理,获取每一层的聚类结果标签; A02-2-4、基于每一层的聚类结果标签,每一层的类保留一个卷积核,在谱聚类的每个 8 CN 111723915 A 说 明 书 4/18 页 类别为一个子图时,选择每个子图中度最大的数据点作为该类的聚类中心; A02-2-5、删除每层所有非聚类中心的卷积核,获得层内剪枝的深度卷积神经网络。 可选地,A02-2-3包括: A02-2-3-1、根据卷积核集合X计算度矩阵D; A02-2-3-2、根据指定方式构建邻接矩阵W; A02-2-3-3、根据度矩阵D、邻接矩阵W计算拉普拉斯矩阵L; A02-2-3-4、进行无向图切图; A02-2-3-5、得到切图结果:子图的集合; A02-2-3-6、每个子图中的卷积核属于同一个类别,赋予同一个类别标签,得到所有卷 积核的类别标签即聚类结果标签。 可选地,采用基于梯度信息的全局剪枝方法对层内剪枝的深度卷积神经网络进行 全局卷积核剪枝处理,获取全局剪枝的深度卷积神经网络,包括: B01、获取进行第i轮层内剪枝处理的全局剪枝率 ; B02、以层内剪枝的深度卷积神经网络中所有的卷积核即全局为单位,基于泰勒展开的 全局卷积核重要性度量计算每一个卷积核重要性信息; B03、根据每一个卷积核的重要性信息及第i轮的全局剪枝率 ,进 行全局卷积核剪枝处理; 其中,i=1时,初始化的全局剪枝的剪枝率为给定数值;待处理的深度卷积神经网络是 给定的网络结构; B04、剪掉重要性低的卷积核,微调减掉重要性低的卷积核的网络中一定的轮数以恢复 该网络的精度,获得全局剪枝的深度卷积神经网络。 可选地,还包括; B05、计算全局剪枝的深度卷积神经网络的联合利用率 ,以及联合利用率的 变化量 ;, ; 其中,联合利用率为全局剪枝的深度卷积神经网络的计算量利用率与参数量利用率之 和; ; ; ; acc为当前网络结构的准确率,FLOPs为当前网络结构的计算量, 为 当前网络结构未剪枝前的网络结构的计算量, 为当前网络的计算量利用率; Params为当前网络结构的参数量, 为当前网络结构未剪枝前的网 9 CN 111723915 A 说 明 书 5/18 页 络结构的参数量, 为当前网络的参数量利用率; 联合利用率的变化量为第i轮剪枝前和第i轮剪枝后的联合利用率的变化量; ; ; 为第i轮聚类剪枝后的联合利用率, 为第i轮全局剪枝后的利用率。 可选地,B02包括: B02-1、全局卷积核重要性的层内正则化; B02-2、根据不同层的卷积核带来的运算次数FLOPs,实现全局卷积核重要性的FLOPs正 则化,获取每一层卷积核的重要性的全局排序; B03包括: 根据每一个卷积核的重要性信息及第i轮的全局剪枝率 ,删除重 要性低的 个卷积核,得到全局剪枝后的网络结构; 其中,剪枝率为β,第i轮层内剪枝后深度卷积神经网络中所有卷积核的数量为N。 第二方面,本发明实施例还提供一种计算机设备,包括:处理器和存储器,所述存 储器中存储指令,所述处理器执行所述存储器中存储的指令,并执行上述第一方面任一所 述的深度卷积神经网络的剪枝方法。 第三方面,本发明实施例还提供一种深度卷积神经网络的应用方法,包括: S1、针对待处理的数据集,基于该待处理的数据集对应的训练数据集,训练深度卷积神 经网络,获取训练后的深度卷积神经网络结构; S2、采用上述第一方面任一所述的深度神经网络的剪枝方法对训练后的深度卷积神经 网络结构进行剪枝处理,获取轻量级的深度卷积神经网络结构; S3、采用轻量级的的深度卷积神经网络结构对待处理的数据集进行分类处理/识别处 理/监测分析,获取处理结果; 或者, S10、采用上述第一方面任一所述的深度神经网络的剪枝方法对一指定的深度卷积神 经网络进行剪枝处理,获取轻量级的深度卷积神经网络结构; S20、采用待处理的数据集对应的训练数据集,训练轻量级的深度卷积神经网络结构, 获取训练后的轻量级的深度卷积神经网络结构; S30、基于训练后的轻量级的深度卷积神经网络结构对待处理的数据集进行分类处理/ 识别处理/监测分析,获取处理结果。 本发明的有益效果是:本发明的方法借助于结构化剪枝的方式,直接删除网络卷 积层中的冗余卷积核,实现处理后的深度神经卷积网络(CNN)无需特定硬件支持的情况下, 在通用硬件平台上实现网络的压缩与加速。 此外,本发明的方法还实现快速获取剪枝后的网络架构,很快提升网络剪枝的效 率。 在本发明实施例中的结构化剪枝是移除整个卷积核,改变了网络的形状,可以不 10 CN 111723915 A 说 明 书 6/18 页 依赖特定的硬件而在通用计算平台(GPU、CPU)上就可以实现真正的网络加速。 因此,通过本发明实施例的结构化剪枝可以同时实现减少网络模型的存储大小 (网络压缩)和降低网络模型的计算开销(网络加速)的目的。 附图说明 图1为本发明一实施例提供的深度卷积神经网络的剪枝方法的流程示意图; 图2为本发明一实施例提供的深度卷积神经网络的剪枝方法的部分流程示意图; 图3为本发明一实施例提供的剪枝方法的框架示意图; 图4为本发明的剪枝方法应用于CIFAR-10数据集上的性能表现的示意图; 图5为在CIFAR-10数据集上VGG-16网络使用本发明的方法剪枝与其他剪枝方案的性能 比较的示意图; 图6为最小化切图的示意图。











