
技术摘要:
本发明公开了一种多声传感器阵列智能感知方法及系统,声目标定位方法包括以下步骤:根据声源空间位置与方位角的转换关系,建立目标声源的方位观测模型,根据方位观测模型确定传播算子算法的空间谱分布;将传播算子算法空间谱分布应用到改进粒子滤波的似然函数中,利用 全部
背景技术:
传统声探测系统,一般将若干个麦克风固定布置在一定区域内,根据麦克风采集 的声信号与预设门限关系判定各个观测点是否存在目标信号。现有多声传感器数据级定位 算法,基于目标回波信号的特殊参数到达各个探测节点与参考点的时间差的测量然后利用 这些测量参数求解定位方程,结合卡尔曼滤波融合得到目标运动参数估计结果后对目标进 行定位。采用现有的方法其存在以下缺陷: 首先,由于基于卡尔曼滤波进行各个探测节点的状态融合,只能应用于线性观测 系统,且系统观测噪声和过程噪声为高斯白噪声,跟踪误差大。
技术实现要素:
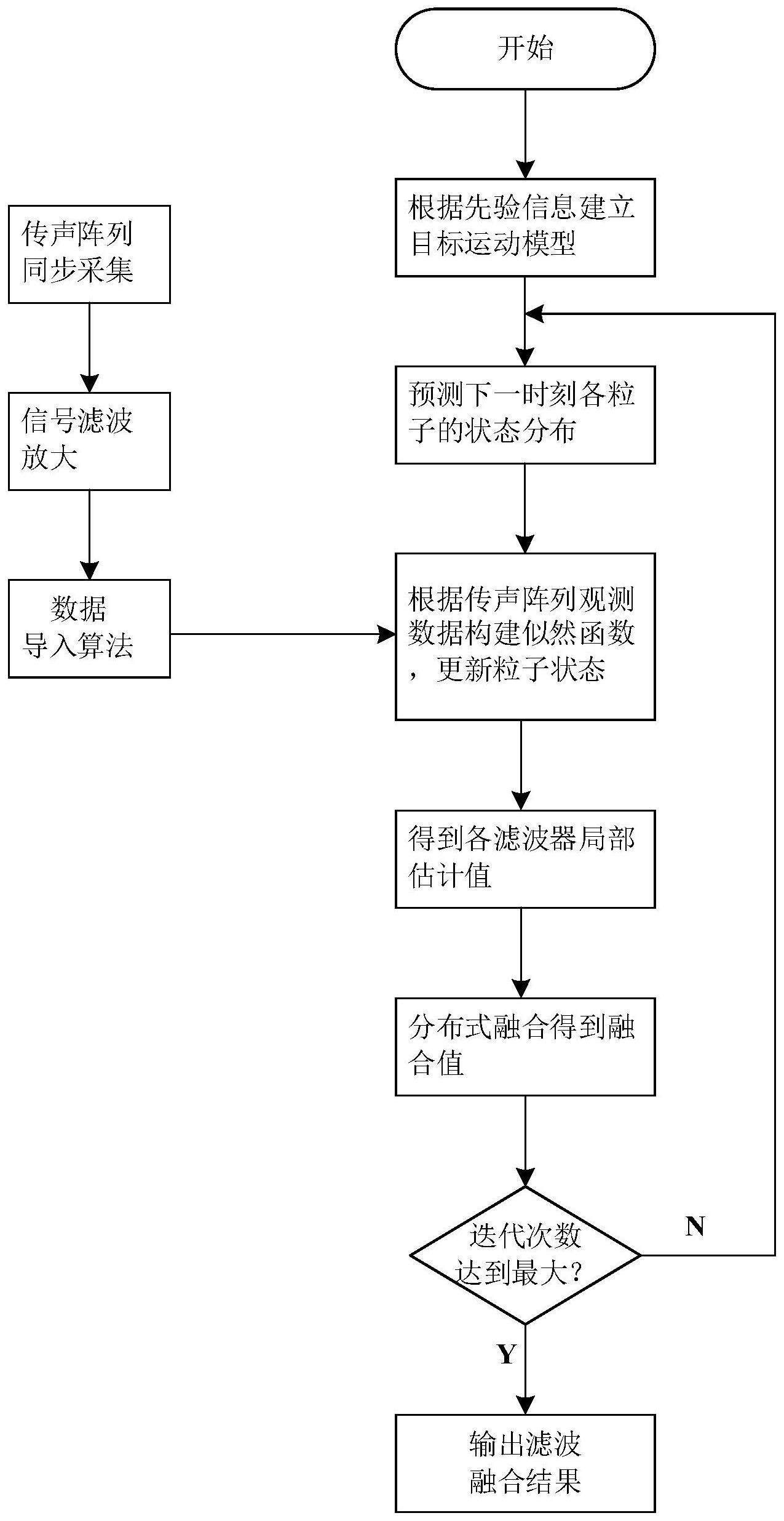
本发明为了解决上述技术问题提供一种多声传感器阵列智能感知方法及系统。 本发明通过下述技术方案实现: 一种多声传感器阵列智能感知方法,包括声目标定位方法,所述声目标定位方法 包括以下步骤: 根据声源空间位置与方位角的转换关系,建立目标声源的方位观测模型, 根据方位观测模型确定传播算子算法的空间谱分布; 将传播算子算法空间谱分布应用到改进粒子滤波的似然函数中,利用粒子滤波方 法分别计算各个传声器阵列对声目标的状态估计值, 根据各个声目标状态估计值,根据标量加权线性最小方差融合准则融合得到目标 的运动状态。 本方案的定位方法基于PF-PM的多传感器阵列的协同跟踪算法,能实现声源的实 时跟踪,融合后的跟踪误差大大降低,提高了声目标的定位精度。 还包括声目标识别方法,所述声目标识别方法包括以下步骤: 获取声目标,对声目标进行多源特征提取与融合,并将未知目标输入人工标注系 统进行人工标注; 输入深度学习网络模型进行训练并识别输出。 传统声目标识别方法需要依赖大量专家经验进行特征提取和分类器设计,不能充 分挖掘目标的深层次特征,识别效果很大程度取决于浅层特征,识别精度低。本方案基于深 度学习网络模型进行实现声目标识别,深度学习是一种利用非线性信息处理技术实现多层 次的特征提取和转换,并进行模式分析和分类的理论方法,可以直接从原始信息中自动学 习、定义和揭示潜在的类别信息,消除噪声影响,并自适应构建决策分类系统,识别精度高, 且可实现对未知目标的学习能力。 4 CN 111610492 A 说 明 书 2/7 页 一种多声传感器阵列智能感知系统,包括声感知节点和集群中枢, 所述集群中枢包括采用上述声目标感定位方法实现声目标定位的声目标定位单 元和采用上述声目标感识别方法实现声目标识别的声目标识别单元。 作为优选,所述声感知节点包括: 采集声音数据时间信息的北斗模块, 用于无线数据传送及自组网的无线传输模块, 采集节点运动状态数据的状态信息采集模块, 用于采集声音信号的传声阵列, 实现对传声阵列的声信号多通道采集的数据采集卡, 实现对上述各模块的控制,实现时间、位置信息解析打包的控制单元。 现有声探测系统根据麦克风采集的声信号与预设门限关系判定各个观测点是否 存在目标信号,由于提取信号参量时会进行门限检测,这样会导致微弱目标无法超过门限 而漏检,导致一些微弱信号损失,使得微弱信号检测环境下的位算法失效。本方案的声感知 节点声音信息采集无门限,可采用微弱的声音信号,避免信息漏检。 本发明与现有技术相比,具有如下的优点和有益效果: 1、本方案基于PF-PM的多传感器阵列的协同跟踪算法,能实现声源的实时跟踪,融 合后的跟踪误差大大降低。 2、本方案的识别方法基于深度学习网络模型,是一种利用非线性信息处理技术实 现多层次的特征提取和转换,并进行模式分析和分类的理论方法,可以直接从原始信息中 自动学习、定义和揭示潜在的类别信息,消除噪声影响,并自适应构建决策分类系统,提高 对声目标的识别精度。 附图说明 此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部 分,并不构成对本发明实施例的限定。 图1为本发明系统的原理框图。 图2为本发明声感知节点的原理框图。 图3为本发明声目标方位的识别方法的流程图。 图4为实施例2的仿真结果图。 图5为实施例3的仿真结果图。 图6为实施例4中角度定位仿真结果图。 图7为深度学习模型的原理图。 图8实施例5的收敛曲线图。











