
技术摘要:
本发明公开了一种化学品知识表示的方法,用于性质复杂的危险化学品领域的知识表示,通过本发明能够完成对危险化学品知识体系的有效管理,对于该领域进行高效的计算和推理研究等提供了极大帮助。该方法主要是:首先确定目标危险化学品并获取其相关信息。接下来使用SMILE 全部
背景技术:
化学品在工农业的生产环节和人们的日常生活中扮演着极为重要的角色,但其中 危险化学品的存在也导致了众多的爆炸、燃烧、毒害等事故,对人体健康和周围环境造成严 重危害。危险化学品的危险性主要是由危化品自身的性质决定的,通常在各种因素的影响 下,通过特定的反应机制表现。掌握其基本性质,对有效防范化学品的危害有关键作用,也 是政府管理部门实施化学品管理决策必备的基础。然而化学品种类繁杂,相互之间差异很 大,掌握其特性十分困难。长期以来,危险化学品领域的从业者都是依赖书籍、网络搜索和 工作经验来规避在生产生活中出现的危险情况。但是书籍和网络搜索的结果依赖于其他从 业者的编辑上传,而且这些资料无法完整地覆盖生产中所有的情况,而单单依赖于工作经 验同样存在经验匮乏,遗忘等风险。因此在互联网飞速发展的今天,如何利用计算机将已有 的数据资料进行整合,进而为危险化学品的安全性防范和生产指导提供帮助已经成为亟待 解决的问题。 知识图谱可以用于描述客观世界中所存在的概念,实体及实体之间的联系,是一 种结构化的工具,其概念的正式提出是在2012年由google定义并宣布将这个技术应用到其 自身的google搜索中。知识图谱可以用形式化的效果来展示已有的数据信息,进而更好地 对繁多复杂的数据进行有效的组织与管理。因此,可以结合知识图谱来表示危险化学品在 客观现实生活的存在,从而更好地将计算机技术应用于危险化学品领域,是一个解决的好 办法。 知识图谱中的知识表示技术是使用张量、图形、向量等方式对知识图谱映射后的 文字信息进行表示的技术,通过知识表示技术更加易于利用知识图谱中的数据进行后续的 推理与应用。结合知识表示技术,可以完成对危化品领域复杂知识的管理,掌握危险化学品 的特性,从而在此技术上完成后续的推理和应用。 对于知识表示学习的研究,从发展历程来看主要可以分成两个阶段。早期的知识 表示学习还处于百花争鸣的阶段,出现了许多的不同的表示模型如能量模型、距离模型、单 层神经网络模型、双线性模型、张量神经网络模型、矩阵分解模型等,它们各自在不同的数 据集上都表现出了一定的优势。2013年,Borders将向量的平移不变性应用于知识表示中, 提出了TransE(Translating Embeddings)这一全新的知识表示模型。TransE模型由其优越 的性能和强大的泛化能力,成为了知识表示领域的标杆模型。在TransE模型提出之后,人们 对于知识的表示方法有了全新的认识,并将知识利用向量进行表示的方法和技巧进行拓展 和深入研究,在其模型基础上进行改良并提出了TransH、TransR、TransD、Transparse、 TransC等模型,共同组成了知识图谱翻译系列模型。 尽管现在知识表示技术已经有了一定阶段性成果,但是现有的知识表示学习模型 4 CN 111613277 A 说 明 书 2/7 页 大多数都被设计为通用模型,对于性质复杂的危险化学品等特定领域的实用性不足,仍然 存在一些缺陷。
技术实现要素:
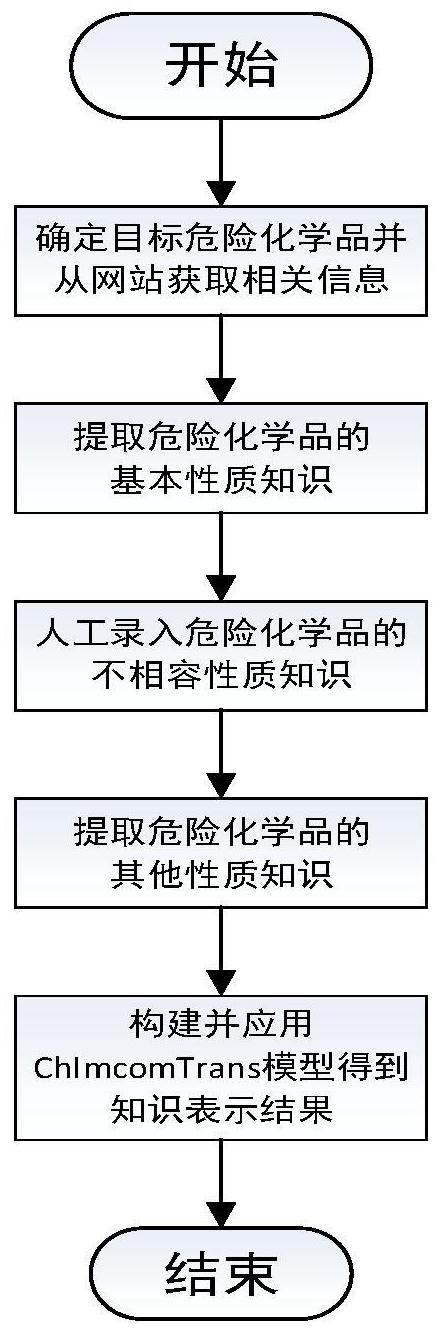
本专利的目的是为现有的危险化学品领域知识提供一种高效率、能够计算和推 理,易于在此基础上进行后续研究的知识表示方法。 具体包括以下步骤: 步骤一,按照《危险化学品目录(2015版)》确定所需的目标危险化学品,然后到网 站上爬取其相关信息,包括了CAS号、SMILES表达式、理化性质、不相容化学品、储存运输方 式等,将上述爬取的相关数据存储至mysql数据库中。 步骤二,提取出危险化学品基本性质知识。对每一个化学品,对其进行SMILES表达 式的解析,将其分解为数个原子、离子和化学基团。将化学品、SMILES表达式、每一个不同的 原子、离子和化学基团均定义为一个实体,再利用SMILES表达式,找出这些实体之间的关 系。将所有的实体和关系组合成三元组信息保存在数据库中。 步骤三,人工录入所有危险化学品之间的不相容性质知识。具体包括两个不相容 实体和实体之间的不相容关系,将所有的不相容信息组合成三元组信息保存在数据库中。 步骤四,提取危险化学品其他性质知识。将数据库中每一条记录中的每一个字段 均定义为一个实体,将化学品相关信息表的列属性名均定义为一个关系,将所有的实体和 关系组合成三元组信息保存在数据库中。 步骤五,构建并应用ChIncomTrans知识表示模型。从数据库中提取所有的三元组 信息,使用ChIncomTrans模型将每个实体和关系都映射到低维向量空间中,使用模型将其 均表示为向量形式的存在,从而完成了知识表示的过程。 进一步限定,所述步骤一中获取的化学品相关信息具体包括以下内容: 中文名、通用俗名、化学品英文名称、英文名、技术说明书编码、生产企业名称、地 址、生效日期、有害物成分、含量、危险性类别、侵入途径、健康危害、环境危害、燃爆危险、皮 肤接触、眼睛接触、吸入、食入、危险特性、有害燃烧产物、灭火办法、应急处理、操作注意事 项、中国MAC、前苏联MAC、TLVTN、TLVWN、监测方法、工程控制、呼吸系统防护、眼睛防护、身体 防护、手防护、其他防护、外观与性状、PH、熔点、沸点、分子式、主要成分、饱和蒸汽压、临界 温度、辛醇水分配系数的对数值、闪点、引燃温度、溶解性、主要用途、其他理化性质、相对水 密度、相对蒸气密度、分子量、燃烧热、临界压力、爆炸上限、爆炸下限、稳定性、禁配物、避免 接触的条件、聚合危害、分解产物、急性毒性、亚急性和慢性毒性、刺激性、致敏性、致突变 性、致畸性、致癌性、生态毒理毒性、生物降解性、非生物降解性、生物富集或生物累积性、其 他有害作用、废弃物性质、废弃处置方法、废弃注意事项、危险货物编号、UN编号、包装标志、 包装类别、包装方法、运输注意事项、法规信息、参考文献、填表部门、数据审核单位、修改说 明、其他信息。 进一步限定,对于步骤二中,对每一个化学式的SMILES表达式的解析过程,将其分 为四种类型。分别是对原子与离子、化学基团、单键化学式和非单键化学式的解析。 第一步,解析SMILES表达式中的原子和离子,包含以下步骤: 先对SMILES表达式找出每个大写字母up作为每一个目标原子或目标离子的开始, 5 CN 111613277 A 说 明 书 3/7 页 再对每一个up之后的字符进行遍历。 若up下一位是“ ”或者“-”号,则目标离子为“up 正负号”。 若up下一位是大写字母或者除了“ ”和“-”外的其他符号,则目标原子为“up”。 若up下一位是小写字母low,则将low添加在up后组成新的目标,继续向后遍历表 达式: 若low下一位是“ ”或者“-”号,则目标离子为“up low 正负号”; 若low下一位是大写字母或者除了“ ”和“-”外的其他符号,则目标原子为“up low”; 若low下一位是数字num,而且数字num后为“ ”或者“-”号,则目标离子为“up low num 正负号”; 若low下一位是数字num,而且数字num后为大写字母或者除了“ ”和“-”外的其他 符号,则目标原子为“up low”; 若up下一位是数字num,继续向后遍历表达式: 若num下一位是“ ”或者“-”号,则目标离子为“up 正负号”; 若num下一位是大写字母或者除了“ ”和“-”外的其他符号,则目标原子为“up”; 将化学品作为一个实体,如图1所得到目标中原子或者离子进行去重操作,之后作 为另一个实体,实体间关系定义为“包含原子”或“包含离子”,将三元组保存在数据库中。 第二步,解析SMILES表达式中包含的化学基团,包括以下步骤: 首先找出SMILES表达式中所有的“[”或者“(”所在的位置作为每一个基团的开始 位置。对每一个开始位置之后的字符串,可以根据当前位置的字符进行SMILES表达式中化 学基团的解析过程: 若表达式当前位置为“[”,符号“[”计数器数值加一,继续向后遍历。 若表达式当前位置为“]”,符号“]”计数器数值减一,若此时计数器数值为0,则当 前位置为基团结束位置,否则继续向后遍历。 若表达式当前位置为“(”,符号“(”计数器数值加一,继续向后遍历。 若表达式当前位置为“)”,符号“)”计数器数值减一,若此时计数器数值为0,则当 前位置为基团结束位置。否则继续向后遍历。 若表达式当前位置为其他字符,继续向后遍历。 将每一个目标化学基团提取出来,将之转化为字符串str,计算str中大写字母的 数量,若大写字母数量大于等于2,则将str定义为一个化学基团实体。 将化学品作为一个实体,化学基团作为另一个实体,实体间关系定义为“包含基 团”,将三元组保存在数据库中。 第三步,解析SMILES表达式中包含的非单键化学式,包括以下步骤: 先找到SMILES表达式中的“=”、“.”、“@”、“#”、“/”、“\”作为非单键化学键。接下来 针对每一个非单键化学键,使用如图3所示解析出非单键化学式,用以提取SMILES表达式中 的信息。起始位置和结束位置的具体寻找方法如下: 首先寻找非单键化学式起始位置。 若化学键的上一位是“]”或者“)”,则使用第二步的方法反向计算,找到其对应的 基团作为起始位置。 6 CN 111613277 A 说 明 书 4/7 页 若化学键的上一位是小写字母low或者正负号,则继续向前搜索到最近的大写字 母up。利用第一步的方法与最长匹配原则找到其对应的原子或者离子作为起始位置。 再寻找非单键化学式结束位置。 若化学键的下一位是“[”或者“(”,则使用步骤第二步的方法,找到其对应的基团 作为结束位置。 若化学键的下一位是大写字母up,则使用第一步的方法和最长匹配原则找到其对 应的原子或者离子作为结束位置。 将化学品作为一个实体,将每一个如图3所解析得到的非单键化学式,定义为非单 键化学式实体,即另一个实体,实体间关系定义为“包含非单键化学式”,将三元组保存在数 据库中。 第四步,解析SMILES表达式中包含的单键化学式及位置信息。 首先遍历化学品的SMILES表达式的每一位,并根据当前位置的字符按照如下方法 来寻找单键化学式及位置信息: 若当前位置的字符是大写字母,则根据第一步中的方法和最长匹配原则计算出原 子或者离子,从结束位置继续向后遍历。 若当前位置的字符是“[”或者是“(”,则根据第二步中的方法计算出化学基团,从 结束位置继续向后遍历。 将上述情况中获得的原子,离子,化学基团依次按顺序编号,则它们的距离定义为 编号的差值,然后按照以下步骤获取SMILES表达式中包含的信息: 若原子,离子,化学基团之间在字符串中的距离dis为1,则将编号较小的化学式定 义为一个实体,编号较大的化学式定义为另一个实体,实体间关系定义为“1_place_ before,将三元组保存在文档中。同时另外定义一个关系为“包含单键化学式”,将这两个三 元组都保存在数据库中。 若原子,离子,化学基团之间在字符串中的距离dis大于1,则将编号较小的化学式 定义为一个实体,编号较大的化学式定义为另一个实体,实体间关系定义为“‘dis’ ‘_ place_before’”,如间隔为3时,实体间关系为“3_place_before”将三元组保存在数据库 中。 进一步限定,对于步骤五中,ChIncomTrans模型训练过程具体为: 第一步,先从数据库中获取所有保存的三元组信息,除了此三元组信息,另外新建 两个文档分别存储实体和关系。 第二步,将实体、关系分别初始化为向量,则每一个三元组可以用三个向量来表 示,表示形式为(头实体向量,关系向量,尾实体向量),用 来表示上述向量。定义 距离向量 用 表示距离向量的大小。 第三步,计算出所有的三元组中每个头实体所对应出现的平均尾实体数 和 每 个 头 实 体 所 对 应 出 现 的 平 均 尾 实 体 数 7 CN 111613277 A 说 明 书 5/7 页 并根据得到的结果确定负样例中替换头实体和尾实体的 概率为 按照此概率对一定数量的正样例三元组信息生 成对应的负样例三元组,将全部新三元组添加到三元组列表中。 第四步,定义损失函数 并利 用梯度下降法更新每个三元组中的头实体向量 实体间关系向量 和尾实体向量 第五步,重复上述第三步和第四步后一定次数或者梯度下降法误差小于训练终止 误差后,最终得到了所有的实体和关系的向量表示结果,从而完成危险化学品领域的知识 表示过程。 本发明的显著效果是为现有的危险化学品领域知识提供一种高效率、能够计算和 推理,易于在此基础上进行后续研究的知识表示方法,通过本发明为危险化学品领域的相 关知识以向量形式进行了映射,完成了知识表示的过程。 附图说明 图1为本发明工作流程图; 图2为解析SMILES表达式中的原子和离子流程图; 图3为解析SMILES表达式中的化学基团流程图; 图4为解析SMILES表达式中的非单键化学式流程图; 图5为解析SMILES表达式中的单键化学式和位置信息流程图; 图6为危险化学品知识库中的部分三元组文档; 图7为三元组中提取的部分实体文档; 图8为三元组中提取的部分关系文档; 图9为ChIncomTrans模型训练过程图; 图10为ChIncomTrans模型映射后得到的部分实体向量表示; 图11为ChIncomTrans模型映射后得到的部分关系向量表示;











