
技术摘要:
本发明提出了一种分布式多智能体时空特征提取方法、行为决策方法。本发明的行为决策方法包括:获取当前时刻及前若干时刻智能体所能感知的状态信息,构建时空状态向量;将时空状态向量输入图网络生成层,输出智能体的原始特征向量;将原始特征向量输入空间特征提取层, 全部
背景技术:
多智能体系统具有分布性、简单性、灵活性和健壮性等优势,为很多极具挑战的复 杂性问题提供了崭新的解决方案,多智能体系统代表的群体智能也是我国《新一代人工智 能发展规划》确立重点发展的五大智能形态之一。随着微纳电子、计算平台、自主控制等新 兴技术的迅猛发展,由无人机、无人车等无人自主平台组成的多智能体系统在关乎国计民 生以及国家和国防安全的重大场景中获得了越来越多的应用。无人自主多智能体系统能以 网络化、分布化、协同化方式快速形成区域覆盖,实现集群资源优化调度,提高任务完成率 和响应速度,一方面可作为一种常态化部署系统,服务于山区巡逻、灾害预警、环境监测、区 域物流等领域,另一方面也可作为一种突发事件的快速响应系统,在诸如疫情防控、突发灾 害、大型活动人防等场景下提供快速物资调度、灾害监测评估、通信保障支援等能力。 多智能体的行为决策主要包括集中式和分布式两种方式。集中式决策拥有一个中 心决策点,所有信息通过通信网络汇聚到中心节点,通过集中的规划决策算法计算所有智 能体的行为决策指令,再经由通信网络将各智能体的决策指令下发给每个智能体执行。集 中式方式对通信网络、中心节点的可靠性要求高,且存在较大的行为延迟,智能体在面向实 际应用场景时难以随着任务、环境变化实现自适应的自主行为决策,极大限制了多智能体 系统智能协同效果的发挥。实际场景中,多智能体系统往往覆盖较大范围,难以形成集中式 网络,且单个智能体往往仅具有有限的环境感知能力、通信能力和行为能力,智能体之间的 通信拓扑连接关系也将在动态任务中时刻发生改变,因此分布式决策将为多智能体系统在 复杂环境和任务中带来更好的自适应能力和任务表现。 智能体在行为决策时,其决策依据为当前任务和环境的状态信息,而面对大规模 集群和复杂任务/环境时,如何采取有效手段对状态信息进行抽象、约简,进而提取出智能 体与智能体之间、智能体与任务环境要素之间的时空特征关系,是保障多智能体系统实现 对任务、环境的抽象理解,进而实现自主决策与智能控制的关键。 图注意力网络是近几年刚刚兴起的一种机器学习方法,其将现实中的诸多问题抽 象为图结构,采用图神经网络进行特征提取,进一步采用注意力机制实现不同特征表示空 间的融合,相关技术在社交网络、交通路况预报等场景中逐步得到验证应用。另一方面,长 短期记忆网络是一种重要的循环神经网络,在时序问题处理上得到了广泛应用,特别是在 语音识别、语义分析等领域。特别地,带窥视孔的长短期记忆网络具有对历史状态反复精炼 的特性,从而在处理复杂状态和时变系统时具有更好的表现。多智能体系统本质的空间拓 扑结构,以及任务的时序依赖性,使得图注意力网络和带窥视孔的长短期记忆网络在多智 能体上具有天然的应用优势,然而由于相关技术刚刚兴起,当前无论是图注意力网络还是 长短期记忆网络,其在由无人机、无人车等组成的无人自主多智能体系统上的应用还鲜有 7 CN 111738372 A 说 明 书 2/14 页 报道,特别是二者相结合用于多智能体系统的时空关系特征提取,无论是在机器学习领域 还是在多智能体系统领域,都具有重要的前瞻创新意义。
技术实现要素:
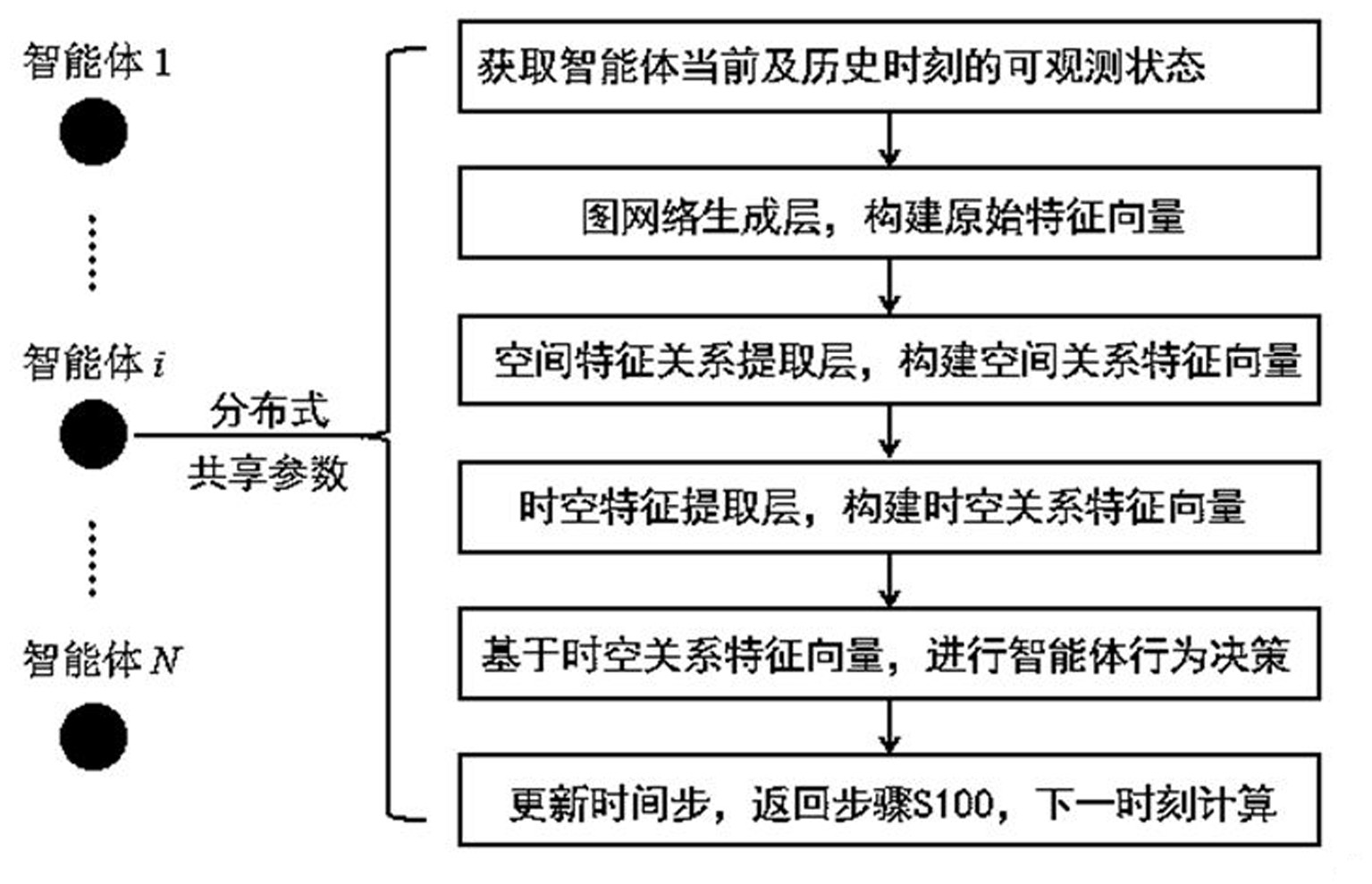
为了解决现有技术中的上述问题,即为了解决多智能体系统在动态、复杂任务中 高效的时空特征关系提取问题,本发明的第一方面提出了一种分布式多智能体时空特征提 取方法,该方法包括以下步骤: 步骤S100,在时刻 ,基于 时刻起每一时刻智能体 可观测到的空间状态向量 ,拼 接 获 取 智 能 体 在 当 前 时 刻 下 的 时 空 状 态 向 量 ;其中, 为预设的历史状态数; 步骤S200,基于 ,通过图网络生成层,获得智能体 的原始特征向量 ;其中, , 为所选特征空间维数; 步骤S300,基于 ,通过空间特征关系提取层,获取智能体 在当前时刻 下的空间 关系特征向量 ;其中,所述空间特征关系提取层采用图注意力网络模块与全连接 网络模块交替堆叠的方式构建; 步骤S400,获取时刻 前 个时刻智能体 的空间关系特征向量 ,将 、 输入到时空特征提取层,并采用基于图卷积运算、带窥视孔的长短期记忆网 络,输出智能体 在当前时刻 下的时空关系特征向量 。 在一些优选实施方式中,步骤S100中“每一时刻智能体 可观测到的空间状态向 量”,包括智能体自身状态、任务目标状态、可观测到的其他智能体状态、可观测到的环境要 素状态; 所述智能体自身状态包括智能体自身位置、速度、加速度状态; 所述任务目标状态包括目标位置、速度状态; 所述可观测到的其他智能体状态包括可观测到的其他智能体的位置、速度状态; 所述可观测到的环境要素状态包括可观测到的环境中障碍物的位置和速度状态、环境 中禁止通行区的位置状态。 在一些优选实施方式中,步骤S200中所述图网络生成层由多层全连接神经网络构 成。 在一些优选实施方式中,步骤S300中基于所述空间特征关系提取层进行空间特征 关系提取的方法包括: 步骤S310,以智能体 的原始特征向量0 以及所有邻居智能体的原始特征向量0 作 为输入,通过第一图注意力网络模块,获得空间关系特征向量1 ;其中, , 为智 能体 能直接通信的邻居智能体集合; 0 , 0 ; 步骤S320,以1 为输入,通过第一全连接网络模块,获得空间关系特征向量2 ; 步骤S330,基于步骤S320方法获得的空间关系特征向量,通过堆叠的图注意力网络模 8 CN 111738372 A 说 明 书 3/14 页 块和全连接网络模块,采用步骤S310、步骤S320的方法迭代计算第 次的空间关系特征向 量 2f-1 、2f ;其中, , 为图注意力网络模块和全连接网络模块的 堆叠层数; 步骤S340,在迭代计算第 次时,基于2(k-1) ,采用步骤S310的方法,通过第 图注 意力网络模块得到空间关系特征向量2k-1 ;将拼接向量[0 , 2 , 4 ,…, 2(k-1) , 2k-1 ]输入第 全连接网络模块,得到第 空间关系特征向量2k ,作为时刻 下智 能体 基于所述空间特征关系提取层的最终输出 。 在一些优选实施方式中,所述空间关系特征向量1 ,其获取方法包括: 步骤S311,采用可学习的矩阵 对关系特征向量0 、0 进行线性变换,并拼接为 一个新的关系特征向量0 =[ 0 , 0 ];将0 输入一个全连接神经网络,输出 智能体 对于智能体 的注意力系数 ;获取智能体 对于智能体 的注意力归一化系 数 , 步骤S312,采用多头注意力机制,对于第 头,采用步骤S311的方法计算归一化注意 力系数 ;计算多头注意力机制融合下智能体 的空间关系特征向量1 , 1 其中, 为记注意力机制头数, 为sigmoid激活函数, 为第 头注意力选 取的线性变换矩阵, 表示向量的拼接操作。 在一些优选实施方式中,所述基于图卷积运算、带窥视孔的长短期记忆网络,包括 个串序连接的、带窥视孔的长短期记忆网络单元; 所述长短期记忆网络单元的输入门、忘记门、输出门基于图卷积神经网络构建。 在一些优选实施方式中,时空关系特征向量 ,其获取方法为: 所述长短期记忆网络中以靠近输出端的长短期记忆网络单元记作 ,并反向进行序 号的增加; 第 个长短期记忆网络单元 的单元状态记作 ,输出为时空关系特征向量 ,输入为 时刻的空间关系特征向量 、第p 1个单元 输出的 时空关系特征向量 及其单元状态 ;其中, ; 基于单元状态记作 、时空关系特征向量 、 、 ,通 过所述长短期记忆网络获得时空关系特征向量 。 9 CN 111738372 A 说 明 书 4/14 页 在一些优选实施方式中,时空关系特征向量 的计算方法为: 步骤401,将 时刻的空间关系特征向量 、第 个单元 的 网络单元状态 以及第 个单元 输出的时空关系特征向量 输入到基 于采用图卷积神经网络的忘记门,计算得到忘记门输出变量 , 其中, *表示图卷积运算, 和 分别为忘记门图卷积神经网络的权重 系数矩阵和偏置, 为sigmoid激活函数; 步骤402,将 时刻的空间关系特征向量 、第 个单元 输 出的时空关系特征向量 及其单元状态 输入到基于采用图卷积神经网络的输入 门,并对单元状态 进行更新,计算公式如下: ; ; 其中, 为输入门的输出, 为单元的过渡状态, 、 为输 入门图卷积神经网络对应的权重系数矩阵, 、 为输入门图卷积神经网络对 应的偏置, 为tanh激活函数, 为哈达玛积; 步骤403,将 时刻的空间关系特征向量 、第 个单元 输 出的时空关系特征向量 以及步骤402更新后的第 个单元 的网络单元状态 输入到基于采用图卷积神经网络的输出门,得到第 个单元 输出的时空关系特 征向量 ,计算公式如下: 其中, 为输出门的输出变量, 、 为输出门图卷积神经网络对 应的权重系数矩阵和偏置。 在一些优选实施方式中,所述分布式多智能体中所有智能体共享可学习的参数。 本发明的第二方面,提出了一种分布式多智能体行为决策方法,基于上述的分布 式多智能体时空特征提取方法,获取智能体 在当前时刻 下的时空关系特征向量 ,采 用基于模型知识驱动的方法或基于强化学习数据驱动的方法,计算智能体 在当前时刻 10 CN 111738372 A 说 明 书 5/14 页 下的行为决策集 ;其中, , 为所选决策空间维数。 在一些分布式多智能体行为决策方法的优选实施方式中,所述分布式多智能体中 所有智能体共享可学习的参数。 本发明的第三方面,提出了一种分布式多智能体时空特征提取系统,包括状态向 量获取模块、原始特征生成模块、空间关系计算模块、时空关系计算模块; 所述状态向量获取模块,配置为在时刻 ,基于 时刻起每一时刻智能体 可观 测到的空间状态向量 ,拼接获取智能体 在当前时刻 下的时空状态 向量 ;其中, 为预设的历史状态数; 所述原始特征生成模块,配置为基于 ,通过图网络生成层,获得智能体 的原始特 征向量 ;其中, , 为所选特征空间维数; 所述空间关系计算模块,配置为基于 ,通过空间特征关系提取层,获取智能体 在 当前时刻 下的空间关系特征向量 ;其中,所述空间特征关系提取层采用图注意 力网络模块与全连接网络模块交替堆叠的方式构建; 所述时空关系计算模块,配置为获取时刻 前 个时刻智能体 的空间关系特征向 量 ,将 、 输入到时空特征提取层,并采用基于图卷积运算、带窥 视孔的长短期记忆网络,输出智能体 在当前时刻 下的时空关系特征向量 。 本发明的第四方面,提出了一种分布式多智能体行为决策系统,基于上述的分布 式多智能体时空特征提取系统,还包括行为决策计算模块; 所述行为决策计算模块,配置为基于智能体 在当前时刻 下的时空关系特征向量 ,采用基于模型知识驱动的方法或基于强化学习数据驱动的方法,计算智能体 在当前 时刻 下的行为决策集 ;其中, , 为所选决策空间维数。 本发明的第五方面,提出了一种存储装置,其中存储有多条程序,所述程序适于由 处理器加载并执行以实现上述的分布式多智能体时空特征提取方法,和/或上述的分布式 多智能体行为决策方法。 本发明的第六方面,提出了一种处理装置,包括处理器、存储装置;处理器,适于执 行各条程序;存储装置,适于存储多条程序;所述程序适于由处理器加载并执行以实现上述 的分布式多智能体时空特征提取方法,和/或上述的分布式多智能体行为决策方法。 本发明的有益效果: 采用分布式的特征提取和行为决策方式,与集中式方式相比,更加贴近大规模多智能 体系统实际应用场景,将充分发挥多智能体系统分布化、网络化、协同化的应用优势;通过 图注意力机制和长短记忆网络对多智能体系统中蕴含的时空特征关系进行提取,可以为多 智能体系统后续智能行为决策提供重要的依据,使得智能体能够在动态、复杂任务中实现 自主行为决策,而采用图神经网络、带窥视孔的长短期记忆网络等参数可学习模型来构建 特征提取层,可实现智能体内部隐藏特征、变化特征的提取,提升智能体的任务、环境适应 性。 11 CN 111738372 A 说 明 书 6/14 页 附图说明 通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它 特征、目的和优点将会变得更明显: 图1是本发明一种实施例的述的分布式多智能体行为决策方法流程示意图; 图2是本发明一种实施例中分布式多智能体时空特征提取方法对于单个智能体 的图 生成层示意图; 图3是本发明一种实施例中分布式多智能体时空特征提取方法对于单个智能体 的空 间特征提取层示意图; 图4是本发明一种实施例中分布式多智能体时空特征提取方法对于单个智能体 的时 空特征提取层示意图; 图5是本发明一种实施例中分布式多智能体时空特征提取方法对于单个智能体 时空 特征提取层中第1个长短期记忆网络单元结构示意图; 图6是本发明一实施例中智能体智能协作行为示意图 图7是本发明一种实施例的分布式多智能体行为决策系统框架示意图。











