
技术摘要:
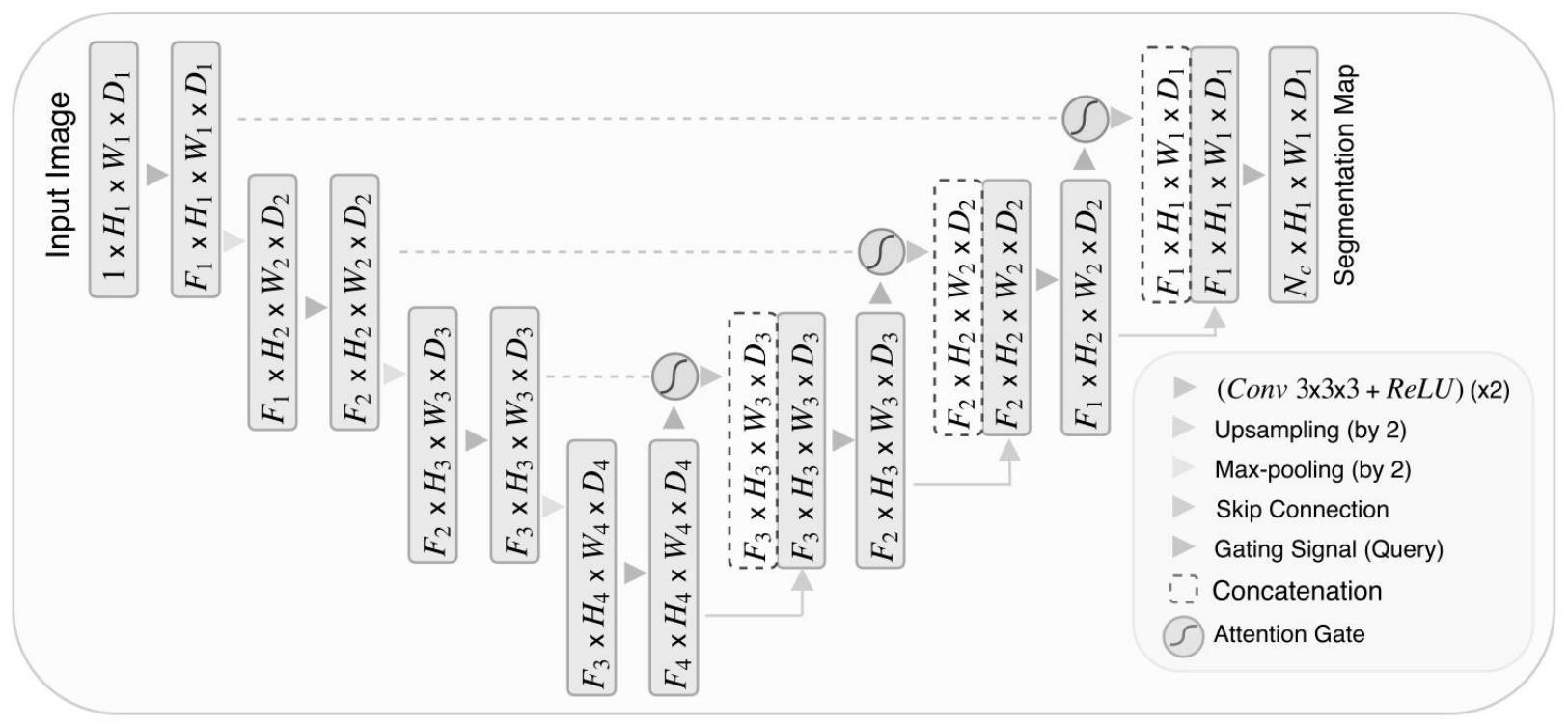
本发明提供一种基于T型注意力结构的医学图像分割方法。本发明提出了一种用于医学图像分割的改进的U‑Net模型,在U‑Net网络的解码网络结构中引入带有T注意力模块的门控注意力机制,在编码网络结构和解码网络结构中加入ResNet残差模块;通过带有T注意力模块的门控注意力 全部
背景技术:
目前由于深度学习的快速发展,对许多领域产生了重大的影响。医学图像分割作 为一种难度较大的视觉任务,遇到的成像数据集的多样性和个体特性是引起人们持久兴趣 的重要原因:在考虑队列大小、图像维数、图像大小、体素强度范围和强度解释时,数据集差 异极大。图像中的类标签可能是高度不平衡的,标签可能是模糊的,而专家注释的质量在不 同的数据集之间有很大的差异。此外,某些数据集在图像几何形状方面是非常不均匀的,或 者可能会出现切片错位。 在目前的医学图像分割领域中,应用最为广泛,效果最好的是U-Net,采用的编码 器(下采样)-解码器(上采样)结构和跳跃连接是一种非常经典的设计方法。但是U-Net网络 的跳跃结构有一个缺点,将每一步上采样的结果不经过处理就连接到解码层导致其浅层特 征可能变换不充分。 近年来,基于全卷积网络的语义分割框架研究取得了显著进展,但是还有一些问 题有待解决,医学图像由于其整幅图像像素之间可能具有很高的关联性,所需要的感受野 比一般的图像要大,全局感受野能够产生最丰富的信息。但是由FCN产生的网络限制了局部 感受野和小范围的上下文信息,之后提出的aspp中的空洞卷积只能收集一些周围像素的信 息,不能产生紧密的上下文信息,金字塔池化也是这样。 为此专家学者提出的一些基于注意力的方法需要产生大的注意力映射去测量每 一对像素的关系。这样效果确实有所提升,但是在时间和空间复杂度都很大,计算量和占用 的内存大,导致训练难度加大。
技术实现要素:
本发明针对传统U-Net中间跳跃结构进行直接融合导致的浅层特征可能变换的不 充分以及减低注意力机制的计算量和占用内存以及训练中梯度消失和爆炸问题,提供一种 基于T型注意力结构的医学图像分割方法。 本发明包括以下步骤: 步骤一、对医学图像数据进行预处理,并进行数据划分得到训练集和测试集; 步骤二、对U-Net网络进行改进,获得预测模型: 在U-Net网络的解码网络结构中引入带有T注意力模块的门控注意力机制,在编码 网络结构和解码网络结构中加入ResNet残差模块; 步骤三、将训练集数据输入预测模型中进行训练; 将训练集输入预测模型中,采用随机初始化和随机梯度下降优化的方法。设置初 始学习率、分割层学习率、动量、权重衰减系数。根据设置好的训练策略进行训练,得到训练 4 CN 111612790 A 说 明 书 2/4 页 后的网络模型; 步骤四、将测试集数据集输入步骤三中训练好的预测模型中,获得分割数据; 进一步的,步骤一对获取的医学图像数据进行预处理,并进行数据划分得到训练 集,验证集和测试集,具体操作如下; 将医学图像大小统一为n*n的正方形形状,将医学图像数据集中百分之八十的样 本作为训练集,剩下的百分之二十的样本作为测试集。在训练和测试阶段采用了基于图像 分块patch-based的方法,将训练集的每一张图片划分成多个小块,每一个小块就称为 patch。将训练集划分的patch90%作为训练数据,10%作为验证数据。 优选的,在步骤二中预测模型包括:编码网络结构和解码网络结构,编码网络结构 包括4个卷积层,3个最大池化层,解码网络结构包括3个上采样层和3个卷积层。其中每个卷 积层包含三个卷积块操作,将编码网络结构和解码网络结构中每一个卷积层的最后两个卷 积块替换成残差卷积块。为了将编码网络结构最后一层和之前更浅层的预测结合起来,加 入跳跃结构将其连接起来,每一层跳跃结构加入一个门控注意力结构进行浅层的输入特征 提取。 所述的门控注意力结构,首先对于输入的编码图像和卷积后的解码图像进行融 合,使用1*1*1的卷积层进行降维操作,再将降维后的图像输入到两个串联T型注意力模块 中,经过T注意力模块后得到的输出再和输入的编码图像进行融合即可得到含有全局信息 的特征图像。 进一步,所述的T型注意力模块从水平和垂直两个方向收集相关信息,增强像素级 的代表性,对于给定的局部特征H,首先进行1*1的卷积操作得到Q,K,V,将Q中的每一个像素 点与K中对应这个点相同的行与列所有像素进行融合操作可以得到A,A与V进行融合操作得 到的结果再与H进行融合就可以得到每个像素点与其相同行列像素点的相关性,将两个T型 注意力模块串联就能够得到全局信息,并且两个T型注意力模块之间共享参数信息。 进一步,步骤三将训练集数据输入预测模型中进行训练,采用随机初始化和随机 梯度下降优化的方法,随机梯度下降优化方法,首先从输入的训练集中随机抽出一组样本 进行训练,训练后按梯度更新一次,然后重新抽取一组样本进行训练,再更新一次,在样本 量大的情况下,不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型, 每次迭代过程中,样本都要被随机打乱。依次设置初始学习率、分割层学习率、动量、权重衰 减系数、迭代次数。训练结束后将验证集输入得到验证结果。 本发明有益效果如下: 本发明提出了一种用于医学图像分割的改进的U-Net模型,通过带有T注意力模块 的门控注意力机制,可以将浅层的输入图像的全局特征信息提取出来,解决了之前因为直 接进行跳跃结构引起的图像特征不充分问题。并且T注意力模块之间共享模型参数,降低时 间和空间复杂度。对于每一个卷积层,加入了残差模块,解决了训练过程中梯度消失和爆炸 问题,网络训练时更容易优化。 附图说明 图1为本发明方法实施例的结构图; 图2为本发明方法实施例的中的门控注意力结构图; 5 CN 111612790 A 说 明 书 3/4 页 图3为本发明方法实施例的T型注意力模块图。











