
技术摘要:
提供了一种从虚拟相机的视点生成被摄体的图像的方法。该方法包括:获取被摄体的多个源图像、以及捕获源图像的一个或多个相机的每一个的姿势数据。还获取指示虚拟相机相对于被摄体的姿势的虚拟相机姿势数据。基于对应源相机的姿势和虚拟相机的姿势中的差异来畸变每个源 全部
背景技术:
在当今时代,视频内容变得越来越沉浸。这在某种程度上是由于HMD的普及,观看 者可以通过HMD观看这些内容。HMD使观看者能够观看部分(在增强现实的情况下)或是完全 (在虚拟现实的情况下)叠加在其世界视图上的内容。在某些情况下,虚拟内容可以以尊重 其所在物理环境(所谓的混合现实)的方式显示给观看者。 在一些应用中,可以向观看者呈现现实生活事件的三维重构。例如,现实生活事件 可以对应于表演者的记录,例如播放一段音乐、呈现内容、在虚构系列中表演等。此类内容 的示例是PS4上可用的“Joshua Bell VR体验”(通过PSVR)。 用于在虚拟现实中呈现表演者的一种已知技术包括捕获表演者的立体视频并将 该视频作为纹理投影到环境的3D重构中的网格上。PCT/GB2018/052671中描述了这种技术 的示例。这种技术在预期观看者的微小的头部运动的情况下往往是足够的;然而,对于更大 的头部运动,该技术的局限性可能变得更加明显。 用于在虚拟现实(VR)中呈现表演者的另一种已知技术涉及使用例如装备在表演 者周围布置多个相机。将相机捕获到的视频用于创建表演者的完整几何模型,然后基于观 看者相对于模型的方向将其适当地显示给观看者。应当理解的是,以这种方式捕获VR内容 是耗时且昂贵的处理。此外,如果没有精确地表示柔性边缘(诸如头发)和复杂的表面材料, 由这样的捕获处理生成的VR内容通常看起来毫无生气。 光场渲染是另一种可以用于在3D中表示对象的技术。然而,光场渲染往往在计算 方面昂贵,而且通常仅限于表示静态对象。 通常,本领域中存在关于不需要过多的数据量或计算处理的情况下在3D中渲染对 象(静态和/或动态)的问题。应当理解的是,如果在视频游戏控制台上执行这种渲染,则可 用的计算能力和资源可能有些有限。此外,如果要在HMD上显示图像,则观看者头部的运动 与从新视点渲染对象之间的任何延迟都可能使观看者感到不舒服。本发明力图解决或至少 缓解其中的一些问题。
技术实现要素:
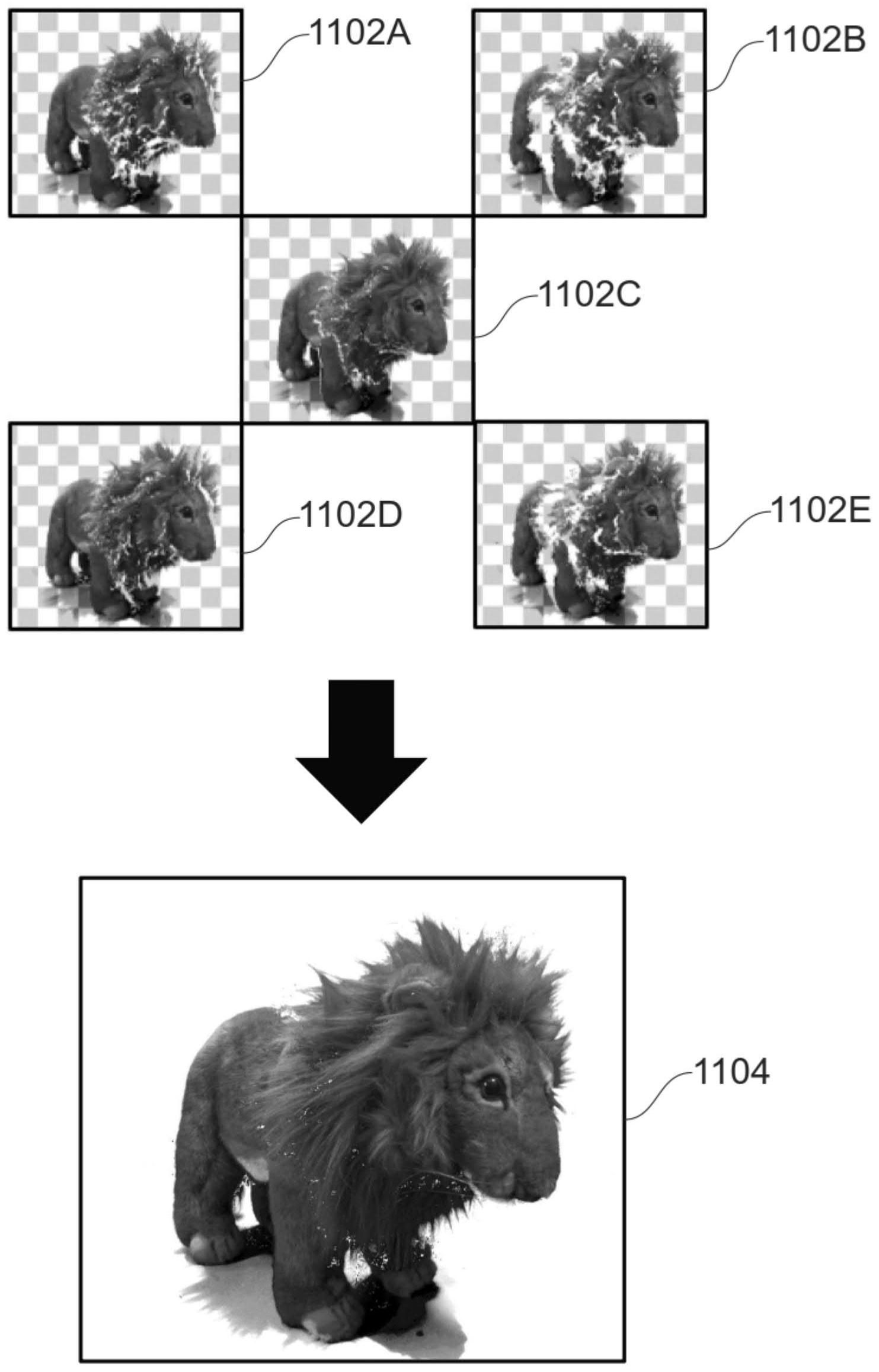
根据本文公开的第一方面,提供了一种根据权利要求1的用于生成在头戴式显示 器(HMD)上显示的被摄体的图像的方法。 根据本文公开的第二方面,提供了一种根据权利要求10的用于生成对象的图像的 系统。 4 CN 111726603 A 说 明 书 2/12 页 附图说明 为了帮助理解本公开并展示如何实施实施例,以示例的方式参考附图,其中: 图1示意性地示出了头戴式显示设备的示例; 图2示出了用于从虚拟相机的视点重构对象的图像的方法的示例; 图3示出了被摄体的示例和用于捕获被摄体的源图像的一个或多个相机的布置; 图4示出了由位于相对于被摄体的不同位置处的一个或多个相机捕获的立体源图 像的示例; 图5示出了为每个对应的立体源图像生成的深度图的示例; 图6A和6B示出了用于为给定的源图像和对应的深度图生成网格的细分处理的示 例; 图7示出了其中可以从网格修剪生成的网格的部分的修剪步骤的示例; 图8A和8B示意性地示出了基于对应的源相机和虚拟相机的姿势之间的姿势差异 而重新投影的网格的部分的示例; 图9示出了用于将源图像的区域映射到对应的重新投影网格的区域的视差映射技 术的示例; 图10A和10B示意性地示出了用于确定与每个畸变图像相关联的权重的方法的示 例; 图11示出了根据本公开生成的畸变图像和通过将这些图像混合在一起而获得的 最终图像的示例;以及 图12示出了用于从虚拟相机的视角生成对象的图像的系统的示例。











