
技术摘要:
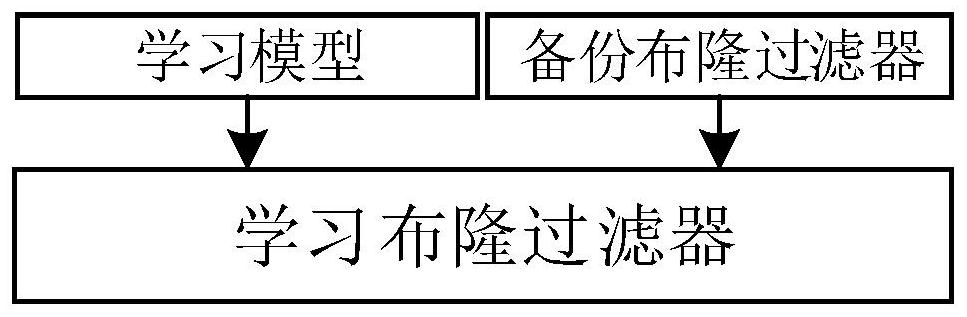
本发明涉及一种基于学习布隆过滤器的ICN网络信息名字查找方法,其查找结构由学习模型和备份布隆过滤器构成,两部分共同组成学习布隆过滤器结构来进行信息名字的查找,首先使用学习模型对信息名字进行查找,但是在提高查找精度的同时会产生一定数量的假阴性,为了将假阴 全部
背景技术:
用户需求决定了网络信息模型。互联网用户的需求从主机之间的通信演进为主机 到网络的信息重复访问。用户关注是信息本身而不是信息的存储位置。而基于TCP/IP的现 有互联网体系结构无法解决当前互联网面临的可扩展性、动态性和安全可控性等根本性问 题。因此为了解决上述问题,并且摆脱传统体系结构对信息的束缚,使信息成为体系结构的 设计中心,ICN(information-centric networking,信息中心网络)被提出。 ICN取代了传统的以地址为中心的网络通信模型,采用了以信息为中心的网络通 信模型,它的通信模式由主机到网络的“拉”式信息访问取代传统主机到主机的“推”式信息 访问,安全机制建立在信息上而不是主机上,转发机制由缓存转发路由取代传统存储转发 路由,从而使信息能够高效传输。 ICN摒弃了传统的以IP为细腰的协议栈结构,采用以信息名字作为核心的协议栈 结构。它采用信息名字作为网络传输的标识,IP地址不被考虑或者只是作为一种底层的本 地化传输标识。这样对用户而言,没有必要去关注网络拓扑,只要按照需求向网络发出数据 请求就可以获得到所请求的信息。在路由过程中,不需要路由到原始数据获取数据源,路径 内的缓存信息可以作为信息源直接回应数据,提高了信息的传输效率。 在ICN中,要想实现对信息的路由,准确的查找到信息尤其重要。ICN网络中信息名 字不像IP网络中的IP地址,它具有多样性,不定长性等特点并且信息名字的数量巨大。因 此,如何从海量的信息名字中准确的找到所需的信息名字是ICN网络研究的一项关键技术。 信息名字的快速准确查找影响了路由的传输效率,同样影响了用户获取信息的效率,在当 前网络环境中,用户对信息的需求量激增,面对海量的信息,对信息名字查找的效率要求更 高。
技术实现要素:
为了解决ICN网络中信息名字查找方法假阳性率高、内存占用量大的问题,本发明 提出一种基于学习布隆过滤器的信息名字查找方法,其利用机器学习,将递归神经网络 (RNN)与标准布隆过滤器相结合,在每个节点处,利用学习布隆过滤器实现信息名字的快速 查找,提高信息名字检索的准确率并降低内存占用量。 本发明的目的及解决其技术问题是采用以下技术方案来实现。依据本发明提出的 一种基于学习布隆过滤器的ICN网络信息名字查找方法,包括以下步骤: 步骤1:路由结点收到兴趣包后,首先在CS中查找兴趣包所需的内容,如果存在,则 销毁兴趣包并生成一个数据包沿兴趣包的反向返回给请求节点; 步骤2:如果CS中不存在所请求的内容,则在PIT中进行查找,如果存在,说明该路 4 CN 111611348 A 说 明 书 2/6 页 由节点已经转发过相同的内容请求,则销毁该兴趣包,并将接收到兴趣包的接口记录在PIT 相应行后边; 步骤3:如果PIT中不存在,则在FIB中查找,如果存在,则将兴趣包按照FIB的接口 转发,并将信息记录在PIT中;如果FIB中不存在,则说明本路由节点不知道该兴趣包的路 由,销毁该兴趣包; 在PIT、FIB和CS中通过查找结构去查找信息名字,其中查找结构由学习模型和备 份布隆过滤器组成, 所述学习模型用于预测信息名字是否在学习模型中,其预测过程如下: 步骤A1:首先用D={(xi,yi=1)|xi∈K}∪{(xi,yi=0)|xi∈U}来训练一个神经网 络,其中,K代表信息名字元素集合,U代表一个非信息名字元素集合; 步骤A2:信息名字x通过一个激活函数 来预测是否在信息集合中的 概率,f(x)的范围属于[0,1]; 步骤A3:输入一个需要查找的信息名字,如果预测出当前样本的输出概率为1,那 么这个信息名属于信息名字元素集合,需要查找的信息名字被查找到; 步骤A4:如果预测出当前样本的输出概率为0,那么这个信息名不在信息名字元素 集合中,代表要查找的信息名字无法被查找到; 所述备份布隆过滤器使用标准布隆过滤器作为查找结构的第二层,目的是将第一 层通过学习模型查找产生的假阴性数量通过再次查找减少为0,其构建的具体过程如下: 步骤B1:利用设置的阈值τ,将使用学习模型产生的假阴性内容建立一个集合:C= {x∈K|f(x)<τ}; 步骤B2:建立一个哈希函数 替代标准布隆过滤器使用的多个哈希 函数,减少内容间的冲突,其中,|K|=m,f(x)为学习模型中的激活函数; 步骤B3:建立一个大小为mbit的标准布隆过滤器; 在PIT、FIB和CS中通过上述查找结构查找信息内容名的步骤如下: 步骤S1、输入内容名元素集合K,非内容名元素集合U,设置一个阈值τ; 步骤S2、调用递归神经网络架构使用集合K和U,训练出一个集合D={(xi,yi=1)| xi∈K}∪{(xi,yi=0)|xi∈U}; 步骤S3、对任意(x,y)∈D,根据激活函数 计算出f(x)的值; 步骤S4、如果x∈K且f(x)≥τ,那么输出x,并且利用最长前缀匹配算法与哈希表进 行匹配,完成匹配后,返回数据包或者将x传递给对应的下一跳; 步骤S5、如果x∈K但是f(x)<τ,那么将内容元素x传递给备份布隆过滤器,并在备 份布隆过滤器中进行再次查找; 步骤S6、通过备份布隆过滤器中的学习哈希函数 生成哈系数,并在 布隆过滤器中对应的bit位进行查找,如果该位的数为1,则输出信息名字x,并且利用最长 前缀匹配算法与哈希表进行匹配,完成匹配后,返回数据包或者将信息内容名x传递给对应 的下一跳; 5 CN 111611348 A 说 明 书 3/6 页 步骤S7、如果生成的哈希值在布隆过滤器中的对应bit位查找出的数为0,则表示 整个查找过程均没有查找到信息名字x,即不存在该信息,那么丢弃这个请求的兴趣包。 所述步骤B3中将备份布隆过滤器建立完成后进行信息名字的插入时步骤如下: 步骤C1:输入内容集合K,选择的阈值τ,布隆过滤器的大小m,插入的信息名字x; 步骤C2:对于插入的信息名字x∈K,首先根据激活函数 计算出一个 概率值; 步骤C3:如果x∈K并且计算的概率值小于设置的阈值τ,利用构造的哈希函数 计算出该信息名字对应的哈希值; 步骤C4:将哈希值对应位置的备份布隆过滤器的元素值加1。 借由上述技术方案,本发明解决了ICN网络中信息名字查找方法假阳性率高、内存 占用量大的问题,其利用机器学习,将递归神经网络(RNN)与标准布隆过滤器相结合,在每 个节点处,利用学习布隆过滤器实现信息名字的快速查找,提高信息名字检索的准确率的 同时降低了内存占用量。 上述说明仅是本发明技术方案的概述,为了能更清楚了解本发明的技术手段,而 可依照说明书的内容予以实施,并且为让本发明的上述和其他目的、特征和优点能够更明 显易懂,以下特举较佳实施例,并配合附图,详细说明如下。 附图说明 图1是本发明具体实施例中学习布隆过滤器的结构示意图。 图2是本发明具体实施例中信息名字查找流程图。











