
技术摘要:
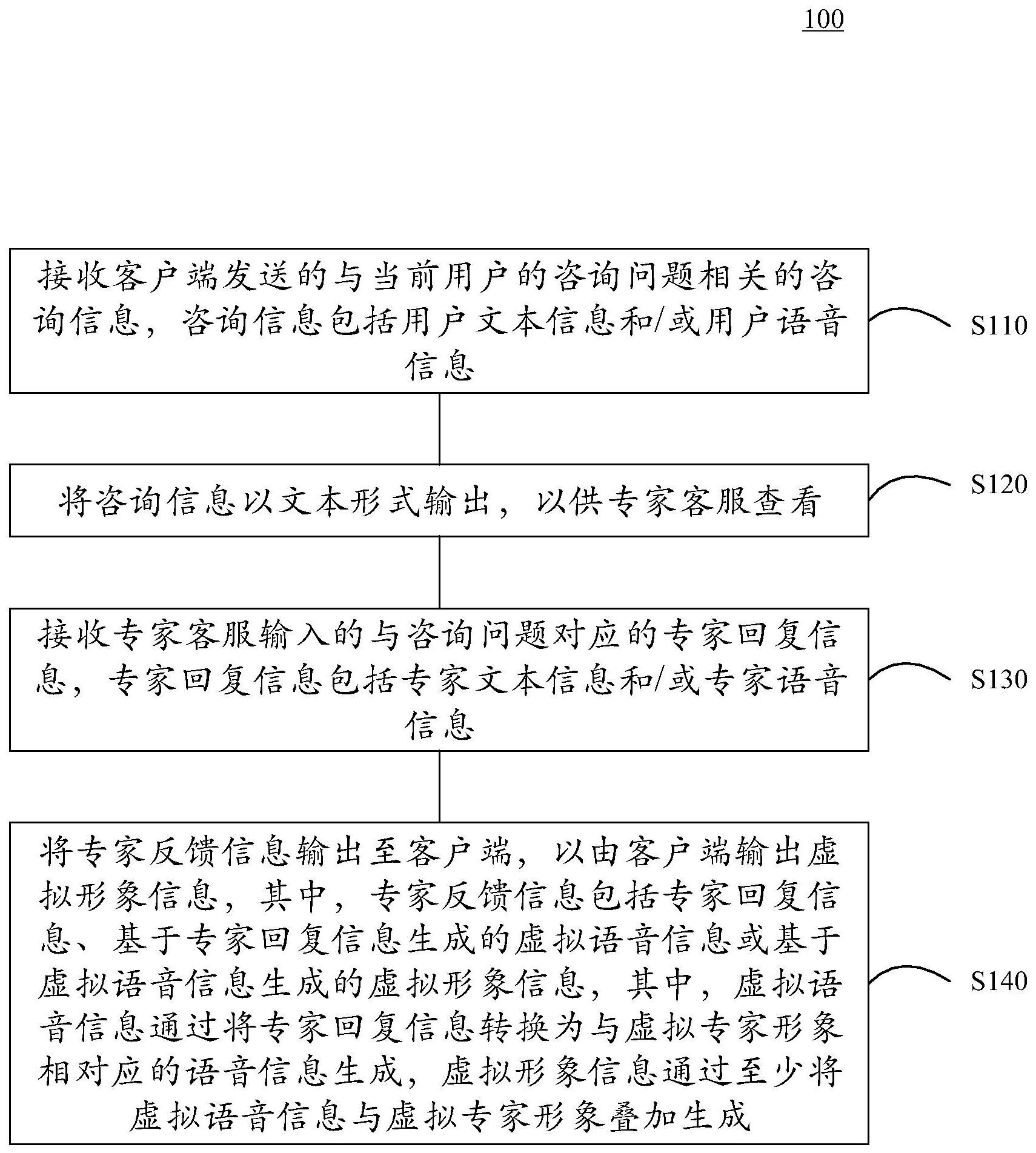
本发明提供一种用于服务端的人机交互方法、服务端与用于客户端的人机交互方法、客户端及存储介质。方法包括:接收客户端发送的与当前用户的咨询问题相关的咨询信息,咨询信息包括用户文本信息和/或用户语音信息;将咨询信息以文本形式输出;接收专家客服输入的与咨询问 全部
背景技术:
目前在金融和银行领域,有大量的专业问题咨询服务,需要专业人员参与。现有的 客户服务方法主要有以下三种: 1 .客户到服务网点进行线下咨询,需要专业的客服人员进行面对面的沟通解答。 这种方式需要客户投入时间成本,缺少隐私保护,有时还有排队的时间投入。金融服务行业 也需要投入固定人力成本,且受到地域条件限制,资源无法有效共享和调配; 2.通过拨打电话的方式,与呼叫中心的客服人员进行语音沟通。该方法虽然不用 到店咨询,但只有语音交互,缺少人和人当面沟通的自然感,表达方式也比较受限; 3.在终端网页或者手机端,通过在线客服入口和后台客服人员进行交流。该方法 减少了用户投入的时间成本,但依然存在由于沟通方式简单、缺少可视化等因素导致的信 息交流效率低、潜在投入成本高的问题。
技术实现要素:
为了至少部分地解决现有技术中存在的问题,提供一种用于服务端的人机交互方 法、服务端及存储介质与一种用于客户端的人机交互方法、客户端及存储介质。 根据本发明一个方面,提供一种用于服务端的人机交互方法,包括:接收客户端发 送的与当前用户的咨询问题相关的咨询信息,咨询信息包括用户文本信息和/或用户语音 信息;将咨询信息以文本形式输出,以供专家客服查看;接收专家客服输入的与咨询问题对 应的专家回复信息,专家回复信息包括专家文本信息和/或专家语音信息;将专家反馈信息 输出至客户端,以由客户端输出虚拟形象信息,其中,专家反馈信息包括专家回复信息、基 于专家回复信息生成的虚拟语音信息或基于虚拟语音信息生成的虚拟形象信息,其中,虚 拟语音信息通过将专家回复信息转换为与虚拟专家形象相对应的语音信息生成,虚拟形象 信息通过至少将虚拟语音信息与虚拟专家形象叠加生成。 示例性地,专家回复信息包括专家文本信息,专家反馈信息包括虚拟语音信息或 虚拟形象信息,在将专家反馈信息输出至客户端,以由客户端输出虚拟形象信息之前,人机 交互方法还包括:对专家文本信息进行语音合成,以获得虚拟语音信息。 示例性地,专家回复信息包括专家语音信息,专家反馈信息包括虚拟语音信息或 虚拟形象信息,在将专家反馈信息输出至客户端,以由客户端输出虚拟形象信息之前,人机 交互方法还包括:对专家语音信息进行音色转换,以转换为虚拟语音信息。 示例性地,专家回复信息包括专家语音信息,专家反馈信息包括虚拟语音信息或 虚拟形象信息,在将专家反馈信息输出至客户端,以由客户端输出虚拟形象信息之前,人机 交互方法还包括:对专家语音信息进行语音识别,以获得对应的识别文字信息;以及对识别 4 CN 111599359 A 说 明 书 2/17 页 文字信息进行语音合成,以获得虚拟语音信息。 示例性地,在将咨询信息以文本形式输出,以供专家客服查看之前,人机交互方法 还包括:基于咨询信息在预设知识库中进行检索,预设知识库用于存储预设问题和与预设 问题对应的预设回复信息;以及在检索到与咨询问题相匹配的特定预设问题时,将知识库 反馈信息输出至客户端,以由客户端输出特定虚拟形象信息,其中,知识库反馈信息包括与 特定预设问题相对应的特定预设回复信息、基于特定预设回复信息生成的特定虚拟语音信 息或基于特定虚拟语音信息生成的特定虚拟形象信息,其中,特定虚拟语音信息通过将特 定预设回复信息转换为与虚拟专家形象相对应的语音信息生成,特定虚拟形象信息通过至 少将特定虚拟语音信息与虚拟专家形象叠加生成;其中,将咨询信息以文本形式输出,以供 专家客服查看的步骤在未检索到与咨询问题相匹配的特定预设问题的情况下执行。 示例性地,在将咨询信息以文本形式输出,以供专家客服查看之前,人机交互方法 还包括:基于咨询问题的类型确定咨询问题的问题等级;其中,将咨询信息以文本形式输 出,以供专家客服查看的步骤在咨询问题的问题等级高于预设问题等级的情况下执行。 示例性地,在将咨询信息以文本形式输出,以供专家客服查看之前,人机交互方法 还包括:接收客户端发送的与当前用户的身份相关的身份相关信息;基于身份相关信息确 定用户的身份信息;以及基于身份信息确定当前用户的客户等级;其中,将咨询信息以文本 形式输出,以供专家客服查看的步骤在当前用户的客户等级高于预设客户等级的情况下执 行。 示例性地,人机交互方法还包括:接收客户端发送的与当前用户的身份相关的身 份相关信息;基于身份相关信息确定用户的身份信息;将身份信息、咨询信息与专家回复信 息关联在一起,并将关联后的信息存储在预设数据库中。 示例性地,身份相关信息包括人脸图像,基于身份相关信息确定用户的身份信息 包括:对人脸图像进行人脸识别,以确定身份信息。 示例性地,咨询信息包括用户语音信息,将咨询信息以文本形式输出,以供专家客 服查看包括:对用户语音信息进行语音识别,以将用户语音信息转写成对应文本信息;以及 将对应文本信息输出,以供专家客服查看。 示例性地,对用户语音信息进行语音识别,以将用户语音信息转写成对应文本信 息包括:对用户语音信息进行语音识别,以获得至少一组候选文本以及与至少一组候选文 本一一对应的至少一个整体得分,每个整体得分用于指示对应候选文本的置信度;确定对 应文本信息包括至少一组候选文本中的选定候选文本,选定候选文本包括至少一组候选文 本中整体得分超过预设阈值的候选文本或者整体得分最高的预设数目的候选文本。 示例性地,对用户语音信息进行语音识别,以获得至少一组候选文本以及与至少 一组候选文本一一对应的至少一个整体得分包括:对语音信息进行语音识别,以获得至少 一组候选文本、至少一个整体得分以及至少一组候选文本中的每个候选文本的每个字的字 得分,每个字得分用于指示对应字的置信度;确定对应文本信息包括至少一组候选文本中 的选定候选文本包括:确定对应文本信息包括选定候选文本以及选定候选文本中的每个字 的字得分。 示例性地,在将咨询信息以文本形式输出,以供专家客服查看之后,人机交互方法 还包括:接收专家客服对对应文本信息中的目标字的选择指令;输出用户语音信息中在目 5 CN 111599359 A 说 明 书 3/17 页 标语音之后的预设时长内的语音信息,以供专家客服查看,其中,目标语音是与目标字对应 的语音。 示例性地,在将咨询信息以文本形式输出,以供专家客服查看之后,人机交互方法 还包括:接收专家客服对对应文本信息中的目标片段的选择指令;输出用户语音信息中与 目标片段对应的语音片段,以供专家客服查看。 示例性地,专家反馈信息包括虚拟语音信息或虚拟形象信息,在将专家反馈信息 输出至客户端,以由客户端输出虚拟形象信息之前,人机交互方法还包括:接收专家客服输 入的风格选择指令;以及将专家回复信息转换为与虚拟专家形象相对应且具有风格选择指 令指示的语音风格的虚拟语音信息。 示例性地,专家反馈信息包括虚拟形象信息,在将专家反馈信息输出至客户端,以 由客户端输出虚拟形象信息之前,人机交互方法还包括:基于专家回复信息生成虚拟语音 信息;基于专家客服的人脸图像生成虚拟专家形象的人物特征;基于虚拟语音信息和人物 特征生成包含具有与虚拟语音信息相匹配的发音动作的虚拟专家形象的虚拟视频信息;以 及至少将虚拟语音信息与虚拟视频信息叠加在一起,以获得虚拟形象信息。 根据本发明另一方面,提供一种用于客户端的人机交互方法,包括:接收当前用户 输入的与咨询问题相关的咨询信息,咨询信息包括用户文本信息和/或用户语音信息;将咨 询信息输出至服务端;接收服务端发送的专家反馈信息,其中,专家反馈信息包括专家回复 信息、基于专家回复信息生成的虚拟语音信息或基于虚拟语音信息生成的虚拟形象信息, 其中,专家回复信息为专家客服输入的与咨询问题对应的回复信息,专家回复信息包括专 家文本信息和/或专家语音信息,虚拟语音信息通过将专家回复信息转换为与虚拟专家形 象相对应的语音信息生成,虚拟形象信息通过至少将虚拟语音信息与虚拟专家形象叠加生 成;基于专家反馈信息获得虚拟形象信息;以及输出虚拟形象信息,以供当前用户查看。 示例性地,专家反馈信息包括专家回复信息,专家回复信息包括专家文本信息,基 于专家反馈信息获得虚拟形象信息包括:对专家文本信息进行语音合成,以获得虚拟语音 信息;以及至少将虚拟语音信息与虚拟专家形象叠加,以获得虚拟形象信息。 示例性地,专家反馈信息包括专家回复信息,专家回复信息包括专家语音信息,基 于专家反馈信息获得虚拟形象信息包括:对专家语音信息进行音色转换,以转换为虚拟语 音信息;以及至少将虚拟语音信息与虚拟专家形象叠加,以获得虚拟形象信息。 示例性地,专家反馈信息包括专家回复信息,专家回复信息包括专家语音信息,基 于专家反馈信息获得虚拟形象信息包括:对专家语音信息进行语音识别,以获得对应的识 别文字信息;对识别文字信息进行语音合成,以获得虚拟语音信息;以及至少将虚拟语音信 息与虚拟专家形象叠加,以获得虚拟形象信息。 示例性地,人机交互方法还包括:将与当前用户的身份相关的身份相关信息发送 至服务端。 示例性地,身份相关信息包括人脸图像。 示例性地,咨询信息包括用户语音信息,将咨询信息输出至服务端包括:对用户语 音信息进行语音识别,以将用户语音信息转写成对应文本信息;以及将对应文本信息输出 至服务端。 示例性地,对用户语音信息进行语音识别,以将用户语音信息转写成对应文本信 6 CN 111599359 A 说 明 书 4/17 页 息包括:对用户语音信息进行语音识别,以获得至少一组候选文本以及与至少一组候选文 本一一对应的至少一个整体得分,每个整体得分用于指示对应候选文本的置信度;确定对 应文本信息包括至少一组候选文本中的选定候选文本,选定候选文本包括至少一组候选文 本中整体得分超过预设阈值的候选文本或者整体得分最高的预设数目的候选文本。 示例性地,对用户语音信息进行语音识别,以获得至少一组候选文本以及与至少 一组候选文本一一对应的至少一个整体得分包括:对语音信息进行语音识别,以获得至少 一组候选文本、至少一个整体得分以及至少一组候选文本中的每个候选文本的每个字的字 得分,每个字得分用于指示对应字的置信度;确定对应文本信息包括至少一组候选文本中 的选定候选文本包括:确定对应文本信息包括选定候选文本以及选定候选文本中的每个字 的字得分。 示例性地,专家反馈信息包括专家回复信息或虚拟语音信息,基于专家反馈信息 获得虚拟形象信息包括:基于专家反馈信息获得虚拟语音信息;基于专家客服的人脸图像 生成虚拟专家形象的人物特征;基于虚拟语音信息和人物特征生成包含具有与虚拟语音信 息相匹配的发音动作的虚拟专家形象的虚拟视频信息;以及至少将虚拟语音信息与虚拟视 频信息叠加在一起,以获得虚拟形象信息。 根据本发明另一方面,提供一种服务端,包括:第一接收模块,用于接收客户端发 送的与当前用户的咨询问题相关的咨询信息,咨询信息包括用户文本信息和/或用户语音 信息;第一输出模块,用于将咨询信息以文本形式输出,以供专家客服查看;第二接收模块, 用于接收专家客服输入的与咨询问题对应的专家回复信息,专家回复信息包括专家文本信 息和/或专家语音信息;第二输出模块,用于将专家反馈信息输出至客户端,以由客户端输 出虚拟形象信息,其中,专家反馈信息包括专家回复信息、基于专家回复信息生成的虚拟语 音信息或基于虚拟语音信息生成的虚拟形象信息,其中,虚拟语音信息通过将专家回复信 息转换为与虚拟专家形象相对应的语音信息生成,虚拟形象信息通过至少将虚拟语音信息 与虚拟专家形象叠加生成。 根据本发明另一方面,提供一种客户端,包括:第一接收模块,用于接收当前用户 输入的与咨询问题相关的咨询信息,咨询信息包括用户文本信息和/或用户语音信息;第一 输出模块,用于将咨询信息输出至服务端;第二接收模块,用于接收服务端发送的专家反馈 信息,其中,专家反馈信息包括专家回复信息、基于专家回复信息生成的虚拟语音信息或基 于虚拟语音信息生成的虚拟形象信息,其中,专家回复信息为专家客服输入的与咨询问题 对应的回复信息,专家回复信息包括专家文本信息和/或专家语音信息,虚拟语音信息通过 将专家回复信息转换为与虚拟专家形象相对应的语音信息生成,虚拟形象信息通过至少将 虚拟语音信息与虚拟专家形象叠加生成;获得模块,用于基于专家反馈信息获得虚拟形象 信息;以及第二输出模块,用于输出虚拟形象信息,以供当前用户查看。 根据本发明另一方面,还提供一种服务端,包括处理器和存储器,其中,所述存储 器中存储有计算机程序指令,所述计算机程序指令被所述处理器运行时用于执行上述用于 服务端的人机交互方法。 根据本发明另一方面,还提供一种客户端,包括处理器和存储器,其中,所述存储 器中存储有计算机程序指令,所述计算机程序指令被所述处理器运行时用于执行上述用于 客户端的人机交互方法。 7 CN 111599359 A 说 明 书 5/17 页 根据本发明另一方面,还提供一种存储介质,在所述存储介质上存储了程序指令, 所述程序指令在运行时用于执行上述用于服务端的人机交互方法。 根据本发明另一方面,还提供一种存储介质,在所述存储介质上存储了程序指令, 所述程序指令在运行时用于执行上述用于客户端的人机交互方法。 根据本发明实施例的用于服务端的人机交互方法、服务端及存储介质与用于客户 端的人机交互方法、客户端及存储介质,专家客服可以同时服务多个客户,使得人效提升, 大大节省了人力资源,并可以有效提升用户体验。 在











