
技术摘要:
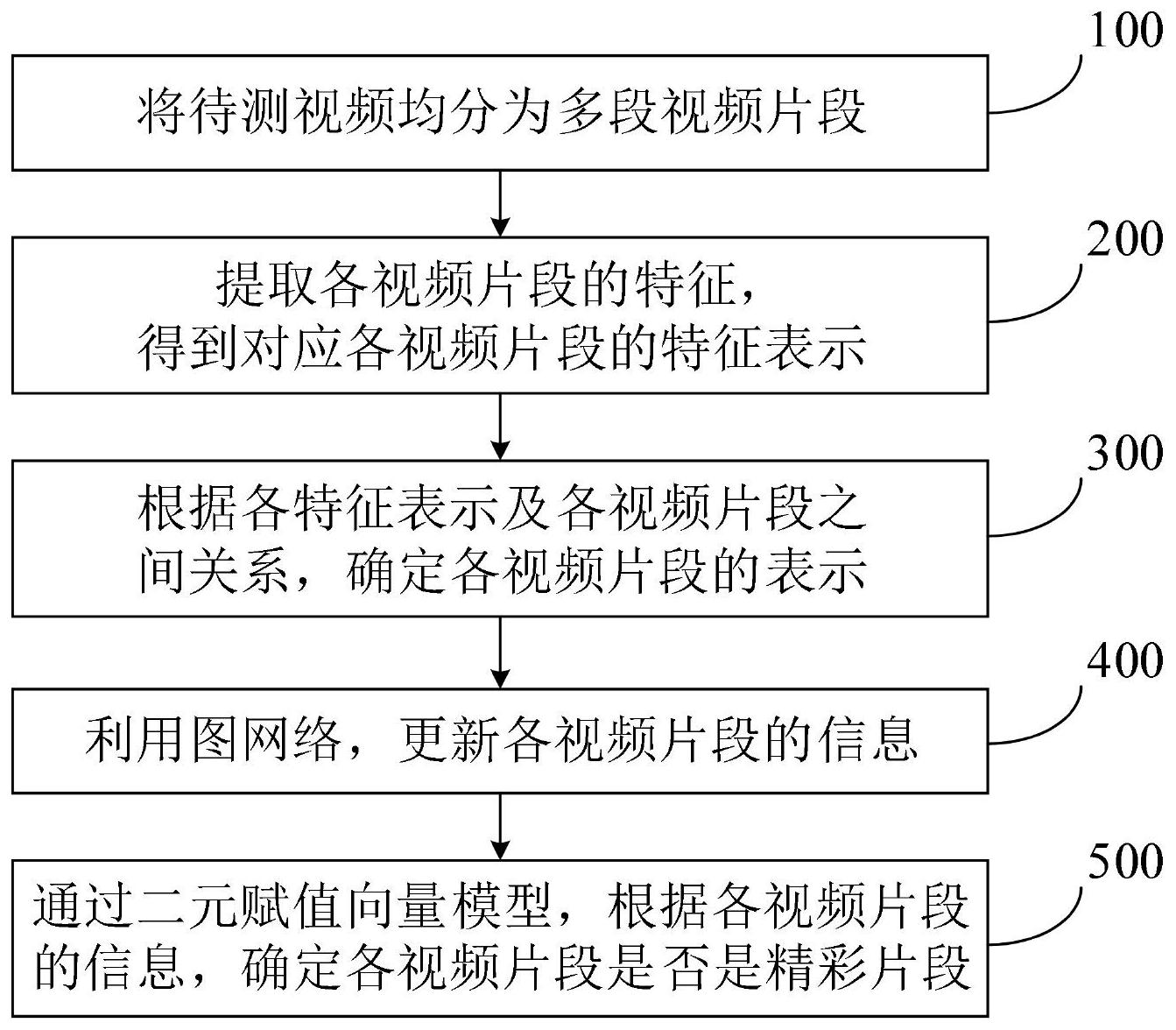
本发明涉及一种视频精彩片段检测方法及系统,所述检测方法包括:将待测视频均分为多段视频片段;提取各视频片段的特征,得到对应各视频片段的特征表示;根据各特征表示及各视频片段之间关系,确定各视频片段的表示;利用图网络,更新各视频片段的信息;通过二元赋值向 全部
背景技术:
随着便携摄像机和智能眼镜等可穿戴设备的普及,越来越多的人通过视频记录自 己的生活,从而使得视频精彩片段检测显得日益重要。 现有的大多数视频精彩片段检测方法都是提取视频整体特征,并没有考虑到时空 局部特征存在差异。由于视频内容的复杂性,这种混合特征将会影响最终精彩片段的检测 效果。 其中,现有视频检测模型主要分成三种,即基于隐变量的排序模型,基于自动编码 器的模型以及基于卷积神经网络的模型。而基于隐变量的模型虽然解决了视频中存在大量 噪声的问题,扩大了训练样本的范围,但由于采用手工特征表示视频,导致检测精度较低; 基于自动编码器的模型降低了对训练数据中负样本数量的要求,但由于整个过程是一个无 监督学习,因此检测精度较低;基于卷积神经网络的模型利用双支网络考虑了视频空间与 时间维度上的信息,但未考虑不同帧提供的信息不同,在同一帧中,不同区域提供的信息也 不同,导致检测信息也不准确。
技术实现要素:
为了解决现有技术中的上述问题,即为了提高视频片段的检测精度,本发明的目 的在于提供一种视频精彩片段检测方法及系统。 为解决上述技术问题,本发明提供了如下方案: 一种视频精彩片段检测方法,所述检测方法包括: 将待测视频均分为多段视频片段; 提取各视频片段的特征,得到对应各视频片段的特征表示; 根据各特征表示及各视频片段之间关系,确定各视频片段的表示; 利用图网络,更新各视频片段的信息; 通过二元赋值向量模型,根据各视频片段的信息,确定各视频片段是否是精彩片 段。 可选地,根据以下公式确定各视频片段的表示: G=(V,E); 其中,G为有向图,用于表示各视频片段;V为节点集合,用于表示视频片段的特征; E为边集合,用于表示为各视频片段之间关系。 可选地,根据以下公式,计算边集合E: 5 CN 111611950 A 说 明 书 2/7 页 其中,H(·)表示特征变换函数, 表示图网络中第l层中第i个节点的特征表示, 表示图网络中第l层中连接第i个节点和第j个节点的边的特征表示;根据 得到边 集合E。 可选地,根据以下公式,得到更新各视频片段的信息 其中, 表示图网络中第l层中传播到第i个节点上的消息, 表示图网络中第l 层中第i个节点的特征表示, 表示图网络中第l层中连接第i个节点和第j个节点的边的 特征表示; 是可学习的权重,σ是softmax函数,M和h均为特征变换函数,ReLU(·)表 示激活函数。 可选地,所述通过二元赋值向量模型,根据各视频片段的信息,确定各视频片段是 否是精彩片段,具体包括: 通过二元赋值向量模型,根据各视频片段的信息,计算各视频片段的特征的模; 选择k个模最大的片段作为精彩片段的候选。 可选地,所述检测方法还包括: 根据检测的结果,确定无监督视频精彩片段检测的损失函数; 根据所述损失函数,对所述二元赋值向量模型更新。 可选地,所述根据检测的结果,确定无监督视频精彩片段检测的损失函数,具体包 括: 通过特征学习网络,学习待测视频的视频片段,得到视频重构的特征: hi=MLP(xi); 其中,xi是第i个片段的预训练的原始特征,hi是用于重构的特征,MLP(·)表示多 层感知器; 根据以下公式,计算得到由精彩片段重构原始视频的特征表示S: 其中,q=[ql,...,qk],qk为第k个候选精彩片段, 表示图网络中第L层中第q个 节点的特征表示; 根据以下公式,计算得到非精彩片段重构原始视频的特征表示u: 6 CN 111611950 A 说 明 书 3/7 页 其中,qC表示q的补集, 表示图网络中第L层中第i个节点的特征表示; 根据以下公式,计算得到原始视频的特征表示v: 其中,maxPool(·)表示最大池化函数,T表示视频片段的数量; 根据以下公式,计算得到重构损失函数Lr(s,v): Lr(s,v)=||s-v||2; 其中,||·||2表示范数; 根据以下公式,计算得到对比损失函数Lc(s,u,v): Lc(s,u,v)=max(0,τ-||u-v||2 ||s-v||2); 其中,τ表示预先设定的阈值; 根据以下公式,计算得到损失函数L: 其中,N表示视频个数,λ是一个平衡项。 为解决上述技术问题,本发明还提供了如下方案: 一种视频精彩片段检测系统,所述检测系统包括: 分段单元,用于将待测视频均分为多段视频片段; 提取单元,用于提取各视频片段的特征,得到对应各视频片段的特征表示; 关联单元,用于根据各特征表示及各视频片段之间关系,确定各视频片段的表示; 更新单元,用于利用图网络,更新各视频片段的信息; 确定单元,用于通过二元赋值向量模型,根据各视频片段的信息,确定各视频片段 是否是精彩片段。 为解决上述技术问题,本发明还提供了如下方案: 一种视频精彩片段检测系统,包括: 处理器;以及 被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处 理器执行以下操作: 将待测视频均分为多段视频片段; 提取各视频片段的特征,得到对应各视频片段的特征表示; 根据各特征表示及各视频片段之间关系,确定各视频片段的表示; 利用图网络,更新各视频片段的信息; 通过二元赋值向量模型,根据各视频片段的信息,确定各视频片段是否是精彩片 段。 为解决上述技术问题,本发明还提供了如下方案: 7 CN 111611950 A 说 明 书 4/7 页 一种计算机可读存储介质,所述计算机可读存储介质存储一个或多个程序,所述 一个或多个程序当被包括多个应用程序的电子设备执行时,使得所述电子设备执行以下操 作: 将待测视频均分为多段视频片段; 提取各视频片段的特征,得到对应各视频片段的特征表示; 根据各特征表示及各视频片段之间关系,确定各视频片段的表示; 利用图网络,更新各视频片段的信息; 通过二元赋值向量模型,根据各视频片段的信息,确定各视频片段是否是精彩片 段。 根据本发明的实施例,本发明公开了以下技术效果: 本发明通过将待测视频均分为多段视频片段,并进行特征提取,得到对应的特征 表示,确定并更新各视频片段的表示,进而通过二元赋值向量模型,可直接确定各视频片段 是否是精彩片段,从而可提高视频片段的检测精度。 附图说明 图1是本发明视频精彩片段检测方法的流程图; 图2是本发明视频精彩片段检测系统的模块结构示意图。 符号说明: 分段单元—1,提取单元—2,关联单元—3,更新单元—4,确定单元—5。











