
技术摘要:
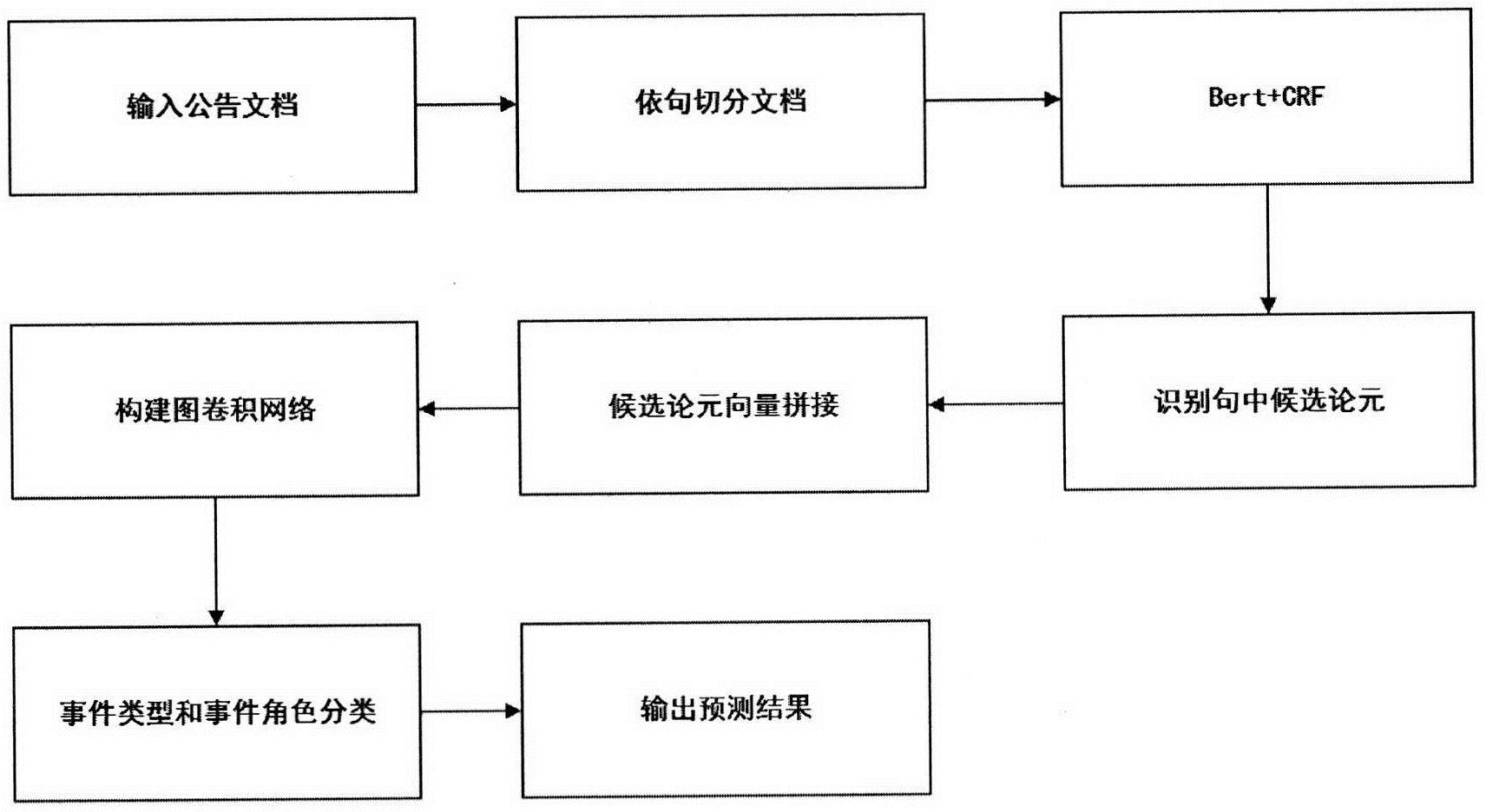
本发明公开了一种基于图神经网络算法的金融篇章级多关联事件抽取方法,首先对输入的语句进行切分,并通过bert crf抽取事件候选元素;其次,构建GCNN节点,获取所述事件候选元素的表征、元素位置编码、所在句表征、句位置编码后拼接成节点表征;然后,构建GCNN边;再其 全部
背景技术:
事件抽取的主要研究方法有模式匹配和机器学习两大类。模式匹配在特定领域内 能取得较高的性能,但移植性较差。在机器学习的抽取方法中,机器学习与领域无关,无需 太多领域专家的指导,系统移植性较好。 1、基于模式匹配的事件抽取 模式匹配方法是在一些模式的指导下进行事件的识别和抽取。模式主要用于指明 构成目标信息的上下文约束环,集中体现了领域知识和语言知识的融合。抽取时只要通过 各种模式匹配算法找出符合模式约束条件的信息即可。由此可见,其核心是抽取模式的构 建。典型的基于模式匹配的事件抽取系统有ExDisco,GenPAM等。起初,模式主要是通过手工 方法来建立的。中国科学院的姜吉发在其博士论文中对模式的自动获取做了深入的研究, 提出了一种基于领域无关概念知识库的事件抽取模式学习方法GenPAM,在模式的学习过程 中,用户只需定义IE任务,无需提供种子模式及对语料分类和标注,系统就能自动从未经分 类和标准的语料中学习出IE模式,大大降低了用户的劳动量和技能要求。 总的来说,基于模式匹配的方法在特定领域内可以取得比较好的效果,但是系统 的可移植性差,从一个领域移植到另一个领域时,需要重新构建模式。而模式的构建费时费 力,需要领域专家的指导。虽然机器学习方法的引入可以从一定程度上加速模式的获取,但 是不同模式之间造成的冲突也是一个棘手的问题。并且,现有研究的语义程度大多停留在 句法层级上,需要进一步提高其语义程度。 2、基于机器学习的事件抽取 采用机器学习的方法识别事件,就是借鉴文本分类的思想,将事件类别及事件元 素的识别转化成为分类问题,其核心在于分类器的构造和特征的选择。但事件分类与文本 分类又有所区别,主要表现在以下方面:分类的文本短,大部分都是一个完整的句子;因为 是事件表述语句,所以语句中包含的信息量大。 大部分研究是基于触发词来进行事件的探测,这种方法简单直观,但触发词只占 所有词的一小部分,这样就在训练中引入大量反例,导致正反例不平衡,并且对每个词判断 会导致计算量的额外增加。为了解决上述问题,已有研究采用了一种基于触发词扩展和二 元分类相结合的方法来识别事件类别。在训练中将触发词收录在词典中并通过同义词林进 行扩展,较好地解决了训练实例正反例不平衡以及数据稀疏问题,在ACE的中文语料上取得 较好的效果。 综上可知,基于机器学习的方法虽然不依赖于语料的内容与格式,但需要大规模 的标准语料,否则会出现较为严重的数据稀疏问题。但现阶段的语料规模难以满足应用需 求,且人工标注语料耗时耗力,为了缓解获取已标注语料的困难,有关学者探究了半监督及 3 CN 111597811 A 说 明 书 2/5 页 无监督的学习研究。另外,特征选取也是决定机器学习结果好坏的重要因素。因此,怎样避 免数据稀疏现象以及如何选择合适的特征,成为基于机器学习方法研究的重要课题。当前 绝大多数研究都是基于短语或句子层级的信息,利用篇章级或跨篇章的信息来提高抽取性 能将成为一个新的热点。 在现有金融篇章级多关联事件抽取方法中,主要存在以下三方面的问题: ①多事件问题:在金融公告数据中存在大量多事件相互关联的复杂抽取任务,这 些关联事件可能包含相同的实体但在各自事件中所充当的角色不一致,或者这些事件之间 无共享实体但事件与事件存在因果或时序关联。这些情况都是导致多事件抽取目前非常困 难的因素,而现有技术无法应对这类难度较大的常见问题。 ②信息分散问题:篇章级的多事件抽取任务中,不同事件常常分散在不同句,并且 距离间隔较远。这种情况下现有技术很难将这些分散而关联的信息考虑全面,而片面的信 息会影响多事件抽取的准确率。 ③现有技术中事件类型、论元信息一般是串联抽取的,这会导致信息损耗、准确率 下降和处理时间更长。
技术实现要素:
本发明的目的在于克服以上存在的技术问题,提供一种基于图神经网络算法的金 融篇章级多关联事件抽取方法。 为实现上述目的,本发明采用如下的技术方案: 一种基于图神经网络算法的金融篇章级多关联事件抽取方法,包括以下步骤: S1:对输入的语句进行切分,并通过bert crf抽取事件候选元素; S2:构建GCNN节点:获取所述事件候选元素的表征、元素位置编码、所在句表征、句 位置编码后拼接成节点表征; S3:构建GCNN边; S4:基于GCNN网络更新所述事件候选元素的表征,并通过linear层 multi- sigmoid层后获取各个元素对应的事件类型和事件角色分类结果; S5:输出抽取的信息。 进一步地,所述步骤S3构建GCNN边的具体方法如下: (1)句向量通过linear层和sigmoid激活层后判断该句是否包含事件信息,若包含 则作为构建图卷积网络边的候选句: (2)连接候选句中存在共享的实体名,其中包括企业名和人名的共指名词或代词; (3)对于存在共享的实体名,将其与出现于同句内的其他事件候选元素建立边。 进一步地,所述步骤S4是通过联合模型实现对事件类型和事件角色分类。 进一步地,通过联合模型实现对事件类型和事件角色分类的具体步骤为: (1)将更新后的事件候选元素集X分为两类,一类为事件关键信息,一类为事件补 充信息; (2)对于事件补充信息类的元素,仅需要判断其所属事件类型后就能对其所充当 的事件角色进行分类;对事件关键信息类的元素,需要采用联合模型实现分类。 进一步地,所述联合模型中,事件类型分类器Ct和事件角色分类器Cr的结构由一 4 CN 111597811 A 说 明 书 3/5 页 个linear层和p个sigmoid层组成,在事件类型分类器中p为4,在事件角色分类器中p为19, 在联合模型中事件类型的分类结果会影响事件角色的分类结果。 本发明的有益效果: 1、本发明所应用的图卷积神经网络弥补了现有其他篇章级事件抽取方法中无法 捕获的句间多事件元素相互关联的信息。图卷积神经网络能够学习到这类非欧空间中网络 节点之间的空间拓扑结构,这对不局限于上下句之间信息抽取的任务有明显优势。另外,随 着GCNN网络层数的累加,还能够学习到网络中更深层的节点关联信息,这都是现有其他方 法无法实现的地方。因此,基于GCNN的算法针对金融公告多事件抽取任务中事件的错综关 联和信息分散等难点上具有明显的优势。 2、为了准确的提取事件元素信息,采用bert CRF的算法结构;并且考虑到bert庞 大的预训练语料和句内上下文语意表征能力可以更精准、更全面的描述GCNN中节点向量及 其所对应句向量。 3、在事件类型(触发词)分类和事件角色分类任务中,考虑到事件角色的类别依赖 于事件的类型,而事件角色的分类结果也有可能反向改变事件类型的分类,通过采用联合 模型来提升两者整体的准确率,并且还能降低了预测时的时间成本。 附图说明 图1:本发明的工作流程示意图。 图2:本发明事件关联向量变换示意图。











