
技术摘要:
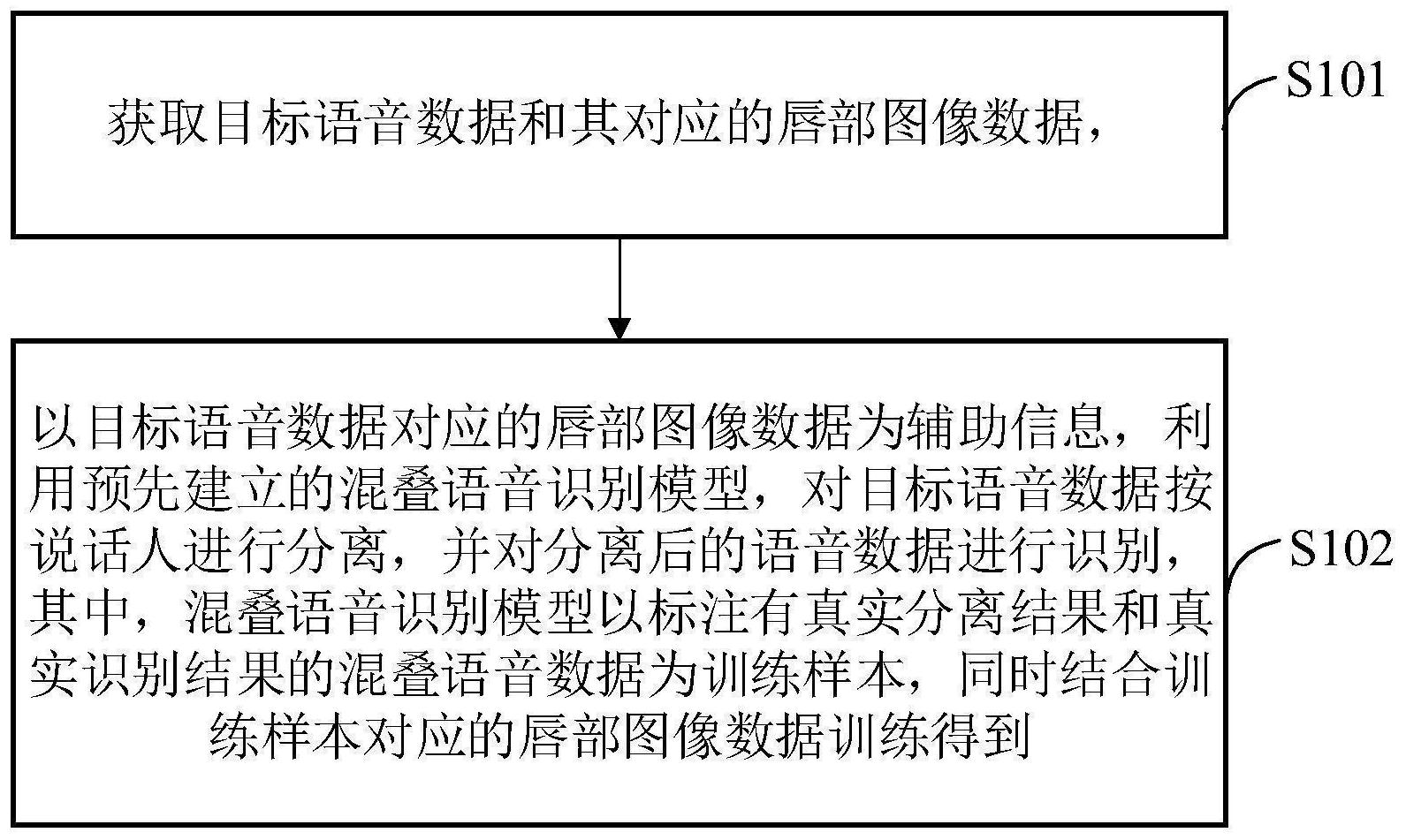
本申请提供了一种语音识别方法、装置、设备及存储介质,其中,语音识别方法包括:获取目标语音数据和其对应的唇部图像数据,其中,唇部图像数据包括目标语音数据所涉及的每个说话人的唇部图像序列;以目标语音数据对应的唇部图像数据为辅助信息,利用预先建立的混叠语 全部
背景技术:
语音识别技术为将语音信号识别为文本的技术。目前比较成熟的语音识别方案主 要为基于语音信号的识别方案,该方案的大致过程为,将待识别的语音信号输入语音识别 模型进行识别,从而获得语音识别结果。 然而,基于语音信号的识别方案对于嘈杂环境下的语音识别效果不佳,尤其是嘈 杂环境下的多人语音,并且,在针对多人语音识别的场景中,可能会出现多个说话人同时说 话的情况,即待识别语音为混叠语音,对于混叠语音,基于语音信号的识别方案很难同时识 别出多个说话人的说话内容。
技术实现要素:
有鉴于此,本申请提供了一种语音识别方法、装置、设备及存储介质,用以解决现 有技术中的语音识别方法对于嘈杂环境下的语音识别效果不佳,且在待识别语音为混叠语 音时,很难同时识别出多个说话人的说话内容的问题,其技术方案如下: 一种语音识别方法,包括: 获取目标语音数据和其对应的唇部图像数据,其中,所述唇部图像数据包括所述 目标语音数据所涉及的每个说话人的唇部图像序列; 以所述目标语音数据对应的唇部图像数据为辅助信息,利用预先建立的混叠语音 识别模型,对所述目标语音数据按说话人进行分离,并对分离后的语音数据进行识别,得到 所述目标语音数据的识别结果; 其中,所述混叠语音识别模型以标注有真实分离结果和真实识别结果的混叠语音 数据为训练样本,同时结合所述训练样本对应的唇部图像数据训练得到。 可选的,所述混叠语音识别模型以最小化分离误差和识别误差为目标训练得到。 可选的,所述以所述目标语音数据对应的唇部图像数据为辅助信息,利用预先建 立的混叠语音识别模型,对所述目标语音数据按说话人进行分离,并对分离后的语音数据 进行识别,包括: 按预设长度对所述目标语音数据切分,由切分得到的目标语音段组成目标语音段 集合; 对于所述目标语音段集合中的每个目标语音段: 利用所述混叠语音识别模型,以及该目标语音段对应的唇部图像数据,对该目标 语音段进行分离; 利用所述混叠语音识别模型,以及该目标语音段对应的唇部图像数据,对分离后 的各语音段进行识别,以得到该目标语音段的识别结果; 5 CN 111583916 A 说 明 书 2/16 页 将所述目标语音段集合中各目标语音段的识别结果融合,得到所述目标语音数据 的识别结果。 可选的,所述利用所述混叠语音识别模型,以及该目标语音段对应的唇部图像数 据,对该目标语音段进行分离,包括: 将该目标语音段输入所述混叠语音识别模型的频谱转换模块,获得该目标语音段 的语音频谱; 将该目标语音段的语音频谱输入所述混叠语音识别模型的第一语音特征提取模 块,获得该目标语音段对应的语音频谱特征; 将该目标语音段对应的唇部图像数据输入所述混叠语音识别模型的图像特征提 取模块,获得该目标语音段对应的唇部图像特征; 将该目标语音段对应的语音频谱特征和唇部图像特征输入所述混叠语音识别模 型的第一特征融合模块,获得第一融合特征; 将所述第一融合特征输入所述混叠语音识别模型的语音分离模块,获得分离后的 各语音段的语音频谱。 可选的,所述利用所述混叠语音识别模型,以及该目标语音段对应的唇部图像数 据,对分离后的各语音段进行识别,包括: 将所述分离后的各语音段的语音频谱输入所述混叠语音识别模型的第二语音特 征提取模块,获得分离后的各语音段分别对应的语音频谱特征; 将所述分离后的各语音段分别对应的语音频谱特征和该目标语音段对应的唇部 图像特征输入所述混叠语音识别模型的第二特征融合模块,获得第二融合特征; 将所述第二融合特征输入所述混叠语音识别模型的语音识别模块,获得分离后的 各语音段分别对应的识别结果。 可选的,获得所述训练样本和所述训练样本对应的唇部图像数据的过程包括: 获取至少两个单人视频段,并将所述至少两个单人视频段合成为一个视频段,得 到合成后视频段,其中,所述合成后视频段中的每帧图像均包括各单人视频段中的说话人, 所述合成后视频段的语音数据为将所述至少两个单人视频段的语音数据进行混叠得到的 语音数据; 从所述合成后语音段中分离出语音数据和图像序列,分离出的语音数据作为所述 训练样本,其中,所述至少两个单人视频段中,每个单人视频段的语音数据的语音频谱作为 所述训练样本的真实分离结果,每个单人视频段的语音数据的文本内容作为所述训练样本 的真实识别结果; 从所述图像序列中获取所述训练样本所涉及的每个说话人的唇部图像序列,作为 所述训练样本对应的唇部图像数据。 可选的,所述混叠语音识别模型的训练过程包括: 按预设长度对所述训练样本切分,由切分得到的训练样本段组成训练样本段集 合; 对于所述训练样本段集合中的每个训练样本段: 利用混叠语音识别模型,以及该训练样本段对应的唇部图像数据,对该训练样本 段进行分离,获得分离后的各样本段的语音频谱,作为该训练样本段的预测分离结果; 6 CN 111583916 A 说 明 书 3/16 页 利用混叠语音识别模型、该训练样本段对应的唇部图像数据以及该训练样本段的 预测分离结果,确定分离后的各样本段分别对应的识别结果,作为该训练样本段的预测识 别结果; 根据该训练样本段的预测分离结果和真实分离结果,确定该训练样本段对应的第 一预测损失,并根据该训练样本段的预测识别结果和真实识别结果,确定该训练样本段对 应的第二预测损失; 根据该训练样本段对应的第一预测损失和第二预测损失,更新混叠语音识别模型 的参数。 可选的,所述混叠语音识别模型包括:语音分离部分和语音识别部分; 所述根据该训练样本段对应的第一预测损失和第二预测损失,更新混叠语音识别 模型的参数,包括: 根据该训练样本段对应的第一预测损失,更新混叠语音识别模型的语音分离部分 的参数; 根据该训练样本段对应的第二预测损失,更新混叠语音识别模型的语音分离部分 和语音识别部分的参数。 可选的,所述根据该训练样本段对应的第一预测损失,更新混叠语音识别模型的 语音分离部分的参数,包括: 按预设的第一权重对该训练样本段对应的第一预测损失加权,以加权后的损失为 依据,更新混叠语音识别模型的语音分离部分的参数; 所述根据该训练样本段对应的第二预测损失,更新混叠语音识别模型的语音分离 部分和语音识别部分的参数,包括: 按预设的第二权重对该训练样本段对应的第二预测损失加权,以加权后的损失为 依据,更新混叠语音识别模型的语音分离部分和语音识别部分的参数; 其中,所述第一权重和所述第二权重均为大于0的值,且所述第一权重与所述第二 权重的和为一固定值。 一种语音识别装置,包括:数据获取模块和语音分离及识别模块; 所述数据获取模块,用于获取目标语音数据和其对应的唇部图像数据,其中,所述 唇部图像数据包括所述目标语音数据所涉及的每个说话人的唇部图像序列; 所述语音分离及识别模块,用于以所述目标语音数据对应的唇部图像数据为辅助 信息,利用预先建立的混叠语音识别模型,对所述目标语音数据按说话人进行分离,并对分 离后的语音数据进行识别,得到所述目标语音数据的识别结果; 其中,所述混叠语音识别模型以标注有真实分离结果和真实识别结果的混叠语音 数据为训练样本,同时结合所述训练样本对应的唇部图像数据训练得到。 一种语音识别设备,包括:存储器和处理器; 所述存储器,用于存储程序; 所述处理器,用于执行所述程序,实现上述任一项所述的语音识别方法的各个步 骤。 一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实 现上述任一项所述的语音识别方法的各个步骤。 7 CN 111583916 A 说 明 书 4/16 页 经由上述方案可知,本申请提供的语音识别方法,首先获取目标语音数据和其对 应的唇部图像数据,然后以目标语音数据对应的唇部图像数据为辅助信息,利用预先建立 的混叠语音识别模型,对目标语音数据按说话人进行分离,并对分离后的语音数据进行识 别,从而得到目标语音数据的识别结果。一方面,本申请在对目标语音数据进行语音分离和 识别时,结合了目标语音数据对应的唇部图像数据,在语音分离和识别时辅以唇部图像数 据,使得本申请提供的语音识别方法对噪声具有一定鲁棒性,且能够提升语音识别效果,另 一方面,本申请采用预先建立的混叠语音识别模型先对目标语音数据进行分离,再对分离 后的语音进行识别,由于混叠语音识别模型以标注有真实分离结果和真实识别结果的混叠 语音数据为训练样本训练得到,因此,利用混叠语音识别模型将不同说话人的语音分离,能 够获得有助于语音识别的语音分离结果,在此基础上进一步利用混叠语音识别模型进行语 音识别,能够获得各说话人较准确的说话内容。本申请提供的语音识别方案除了对非嘈杂 环境下的非混叠语音具有较好的识别效果外,对于嘈杂环境下的混叠语音也具有较好的识 别效果。 附图说明 为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据 提供的附图获得其他的附图。 图1为本申请实施例提供的语音识别方法的流程示意图; 图2为本申请实施例提供的获取训练样本和训练样本对应的唇部图像数据的流程 示意图; 图3为本申请实施例提供的混叠语音识别模型的训练过程的流程示意图; 图4为本申请实施例提供的混叠语音识别模型的一拓扑结构的示意图; 图5为本申请实施例提供的利用混叠语音识别模型,以及训练样本段对应的唇部 图像数据,对训练样本段进行分离的流程示意图; 图6为本申请实施例提供的利用混叠语音识别模型、训练样本段对应的唇部图像 数据以及训练样本段的预测分离结果,确定分离后的各样本段分别对应的识别结果的流程 示意图; 图7为本申请实施例提供的以目标语音数据对应的唇部图像数据为辅助信息,利 用预先建立的混叠语音识别模型,对目标语音数据按说话人进行分离,并对分离后的语音 数据进行识别的流程示意图; 图8为本申请实施例提供的语音识别装置的结构示意图; 图9为本申请实施例提供的语音识别设备的结构示意图。











